| Torno ad effettuare uno dei miei rari post in questo forum, ancora una volta per supporto ad una discussione esterna a questo Forum. In questo caso, tratto della evoluzione di questa risposta data alla domanda dello utente "marioma86" CITAZIONE Buonasera a tutti, con il supporto del forum sono riuscito a scrivere un programma che mi permette di creare un file csv a partire da un pdf:
import pdftotext
import csv
with open('18567.pdf', 'rb') as pdf_file:
pdf = pdftotext.PDF(pdf_file)
lines = pdf[0].splitlines()[20:23]
table = []
for line in lines:
table.append(line.split())
with open("prova2pdf.csv", "w") as csv_file:
writer = csv.writer(csv_file, delimiter=";")
writer.writerows(table)
Copy
A questo punto vorrei implementare un programma che mi permetta, attraverso un'interfaccia grafica, di selezionare il pdf e poi creare il csv; di seguito il codice che ho scritto ma che purtroppo genera errori: cui diedi un veloce esempio di codice che crea la finestra in figura 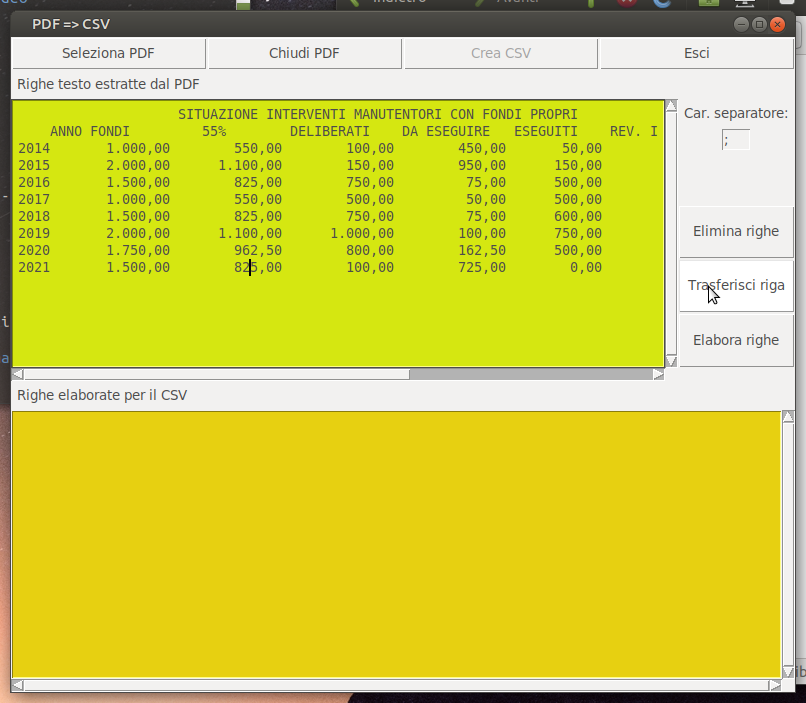
La finestra è in grado di aprire un pdf testuale ed estrarne le righe di testo per posizionarle in una text-box tkinter, permette inoltre di :
- eliminare le linee superflue
- editare a mano righe con "imperfezioni" e trasferirle in una text-box per il csv
- definire il carattere separatore dei dati
- elaborare blocchi di righe inserendo il carattere separatore impostato al posto degli spazi
- creare il file csv desiderato
Il semplice esempio in link si ferma alla prima pagina del pdf, situazione di cui @mauroma86 si era detto soddisfatto, comunque, nel prosieguo del post in link si trovano anche le indicazioni necessarie ad aprire tutte le pagine di un pdf da trattare. Comunque, l'appetito vien mangiando (è il bello della programmazione  ) e @mauroma86 ha posto ulteriori domande : CITAZIONE @nuzzopippo ho seguito il tuo consiglio e sto approfondendo le classi.
Per migliorare eventualmente il progetto volevo chiederti se, secondo te, fosse possibile una volta definite le righe da importare nel csv, scegliere anche quali colonne eventualmente eliminare (perchè non serve indicarle nel csv) e scegliere, eventualmente, come delimitatore la tabulazione.
Per apportare queste modifiche, ora ho creato un workflow utilizzando Knime, un software di data science; vorrei, però, integrare questa funzione direttamente nel codice dell'applicativo.
Pensi che possano essere delle modifiche fattibili? Ovviamente, può essere fatto, senza alcun bisogno di scomodare librerie per il calcolo scientifico, è una problematica estremamente semplice, questo post spiega un possibile metodo di esempio e ne fornisce il codice (poco meno di 400 righe, troppe per il forum riferito su) In primo luogo, premetto che tutti i test sono stati eseguiti sul pdf, da me creato, in figura sotto 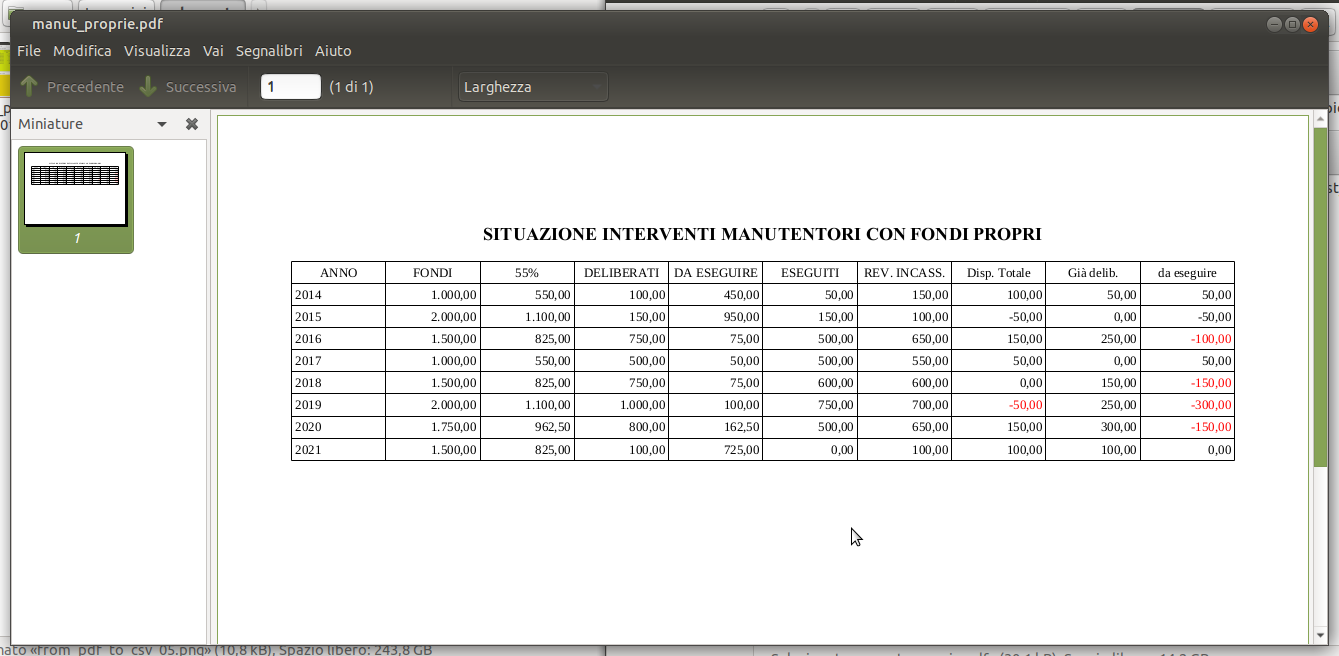
che risponde a quello che "dovrebbe" essere un file csv canonico, ossia una bella tabella piatta con una riga di intestazione ed una serie di righe a colonne uniformi ... anche se non è rispettata la clausola "codifica in ASCII" ... dopo tutto NON la rispetta nessuno e renderebbe moolto più ampio quello che è solo un esempio  Il primo quesito posto : scegliere quali colonne eliminarepuò essere fatto in vari modi, più o meno sofisticati a seconda di quanto ci si voglia dedicare, un metodo decisamente elementare è caricarsi l'intero set dei dati come se dovessero essere esportati tutti nel csv per poi caricarsi la prima riga dati, che di norma dovrebbero essere le intestazioni di colonna, ed eliminare quelle che non si vogliono salvare. Una finestra dedicata alla "faccenda" è un ottimo modo per tenere separa tale parte di logica, che necessariamente ha una forte interazione con l'utente, dal resto, decisamente più "automatizzabile", ed inoltre eviterebbe di sovra-caricare di controlli la finestra principale. Naturalmente, per utilizzare una finestra "aggiuntiva" bisognerà alterare la finestra principale tanto nella struttura quanto nell'aspetto, che assumerò una forma leggermente diversa 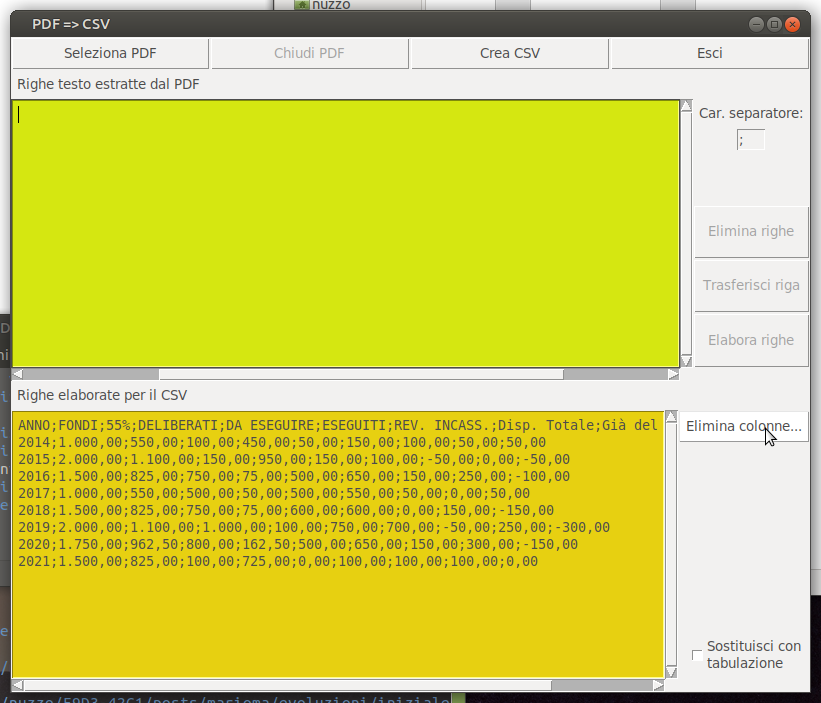
dovendo disporre dei comandi e delle opzioni richieste, in figura, che riporta la condizione con il pdf già completamente trattato per la impostazione del csv, vedete la presenza del pulsante " Elimina colonne..." la cui funzione di callback associata ("self._gest_columns()") istanzia un oggetto "S etNoRead" che produce la finestra sotto 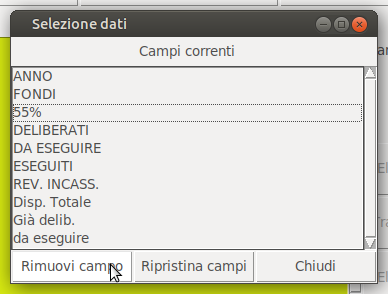
... può essere interessante guardare il callback CODICE def _gest_columns(self):
self.state = 'remove_data'
self.source_data = self.csv_text.get('1.0', 'end').split('\n')
text = self.csv_text.get('1.0', '1.end')
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
labels = text.split(sep)
dlg = SetNoRead(self, labels, self.no_read)
dlg.grab_set() qui si possono osservare contemporaneamente tre modifiche "strutturali" della finestra principale :
- self.state : non utilizzata e messa li per "sviluppi futuri"
- self.source_data : che memorizza, suddiviso in righe, il contenuto corrente della text-box dedicata al csv elaborato
- self.no_read : dedicato alla memorizzazione delle colonne da NON riportare nel csv finale
da notarsi, anche, l'elaborazione della prima riga di testo presente nel text csv per definire " labels", una lista delle intestazioni di colonna (nelle intenzioni) che permetterebbe di semplificare la selezione delle colonne da non considerare da La gestione delle colonne, nell'oggetto "SetNoRead", è semplificata al massimo, le "labels" ricevute al momento dell'istanza vengono inserite in un widget listbox, tutto ciò che si deve fare è selezionare nella list-box una colonna che si vuole eliminare e premere il pulsante " Rimuovi Campo" la cui funzione di callback CODICE def _remove_item(self):
indexes = self.lst.curselection()
if not indexes: return
for i in indexes:
item = self.lst.get(i)
try:
index = self.labels.index(item)
self.no_read.append(index)
self.master.evaluate_data()
except ValueError:
return
self.lst.delete(i) rileverà dalla list-box l'indice dell'elemento selezionato e lo aggiungerà alla variabile di istanza "self.no_read", che altro non è che lo stesso "self.no_read" della finestra principale, fatto questo invoca il metodo pubblico "evaluate_data()" della finestra principale, con l'istruzione " self.master.evaluate_data()". ... Forse è il caso di guardare un po' quest'ultimo metodo della finestra principale CODICE def evaluate_data(self):
self.csv_text.configure(state='normal')
if not self.source_data: return
self.csv_text.delete('1.0', 'end')
if not self.no_read:
for row in self.source_data:
self.csv_text.insert('end', row + '\n')
else:
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
for row in self.source_data:
items = row.split(sep)
data_view = []
for i in range(len(items)):
if not i in self.no_read:
data_view.append(items[i])
text = sep.join(data_view)
self.csv_text.insert('end', text + '\n')
self.csv_text.configure(state='disabled') Tale metodo della finestra principale è stato definito apposta (con altri) per permettere una sorta di comunicazione tra la finestra "master" e le finestre figlie, che ne devono essere a conoscenza, è molto più sbrigativo ed anche molto meno portabile ed elastico di un pattern MCV ma "può andare", provvede a valutare la lista degli indici di colonna esclusi, se è vuota si limita a cancellare il contenuto della text-box per il csv e reinserire le righe memorizzate in self.source_data così come sono, altrimenti estrae gli elementi di ogni singola riga di self.source_data e costruisce una nuova riga con quelli il cui indice risulta essere registrato in self.no_read. Il risultato delle operazioni appena dette sarà la sparizione della etichetta nella lista della finestra figlia e della colonna dati nella finestra madre In rigura il risultato della eliminazione dela campo "55%" 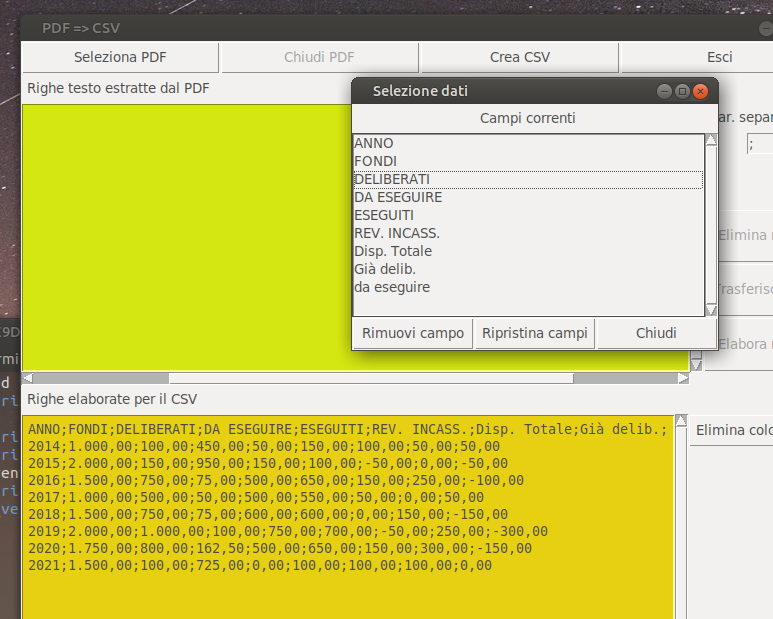
In caso di errori la pressione del pulsante " Ripristina campi" della finestra figlia azzererà le modifiche apportate, ho scelto di non chiudere la finestra (anche se sarebbe stato bene farlo) per lasciar spazio ad eventuali gestioni più sofisticate. Vorrei portare l'attenzione sulla funzione di callback del pulsante " Chiudi" della finestra figlia CODICE def _close(self):
self.grab_release()
self.destroy()
self.master.close_evaluate_data() esso, in primo luogo rilascia la gestione esclusiva degli eventi, acquisita al momento della sua istanza (istruzione "dlg.grab_set()" del callback "_gest_columns(self)" nella finestra principale, distrugge la finestra figlia e poi invoca il metodo "close_evaluate_data()" della finestra madre (self.master) che svuota il "seòf.state" ed il "self.source_data" ma NON svuota il self.no_read della finestra principale ... forse qualcuno si chiederà il perché : è un invito!Nelle intenzioni l'esempio è concluso, circa la definizione del csv ma, volendo si potrebbero aprire ulteriori pdf ed aggiungerli, in tal caso si potrebbe adattare la logica di trasferimento dati in modo tale che consideri le esclusioni definite ... agli interessati la giusta implementazione. Rimane l'ultimo punto richiesto da @mauroma86 : impostare quale delimitatore la tabulazione... basterebbe leggere lo " Unicode HOWTO", sezione " The String Type" (devo decidermi a tradurmelo) e fare qualche prova, nel mio sistema (linux 64 bit) si riesce utilizzando la notazione unicode esadecimale a 32 bit " \Uhex_num" In presenza di selezione della casella " Sostituisci con tabulazione" 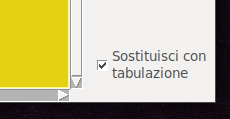
il callback "_make_csv" della finestra principale sostituisce nel testo da scrivere tutti i caratteri separatore contenuti CODICE if self.chk_var.get():
sep = self.e_sep.get()
text = text.replace(sep, '\U00000009') Ed ora il codice completo (376 righe) CODICE # -*- coding: utf-8 -*-
import os
import tkinter as tk
import tkinter.messagebox as msgb
import tkinter.filedialog as fdlg
import pdftotext
class SetNoRead(tk.Toplevel):
def __init__(self, master, labels, no_read, *args, **kwargs):
super().__init__(master, *args, **kwargs)
self.title('Selezione dati')
self.master = master
self.labels = labels
self.no_read = no_read
p_dlist = tk.Frame(self)
p_dlist.grid(row=0, column=0, sticky='nsew')
lbl = tk.Label(p_dlist, text='Campi correnti', padx=5, pady=5, justify='left')
lbl.grid(row=0, column=0, sticky='ew')
self.lst = tk.Listbox(p_dlist, selectmode=tk.MULTIPLE)
self.lst.grid(row=1, column=0, sticky='nsew')
scr_lst = tk.Scrollbar(p_dlist, command=self.lst.yview)
self.lst.configure(yscrollcommand=scr_lst.set)
scr_lst.grid(row=1, column=1, sticky='ns')
p_dlist.grid_rowconfigure(1, weight=1)
p_dlist.grid_columnconfigure(0, weight=1)
p_buttons = tk.Frame(self)
p_buttons.grid(row=1, column=0, sticky='ew')
bt_remove = tk.Button(p_buttons, text='Rimuovi campo', padx=5, pady=5,
command=self._remove_item)
bt_remove.grid(row=0, column=0, sticky='ew')
bt_restart = tk.Button(p_buttons, text='Ripristina campi', padx=5, pady=5,
command=self._reset_items)
bt_restart.grid(row=0, column=1, sticky='ew')
bt_close = tk.Button(p_buttons, text='Chiudi', padx=5, pady=5,
command=self._close)
bt_close.grid(row=0, column=2, sticky='ew')
p_buttons.grid_columnconfigure(0, uniform=1, weight=1)
p_buttons.grid_columnconfigure(1, uniform=1, weight=1)
p_buttons.grid_columnconfigure(2, uniform=1, weight=1)
self.grid_rowconfigure(0, weight=1)
self.grid_columnconfigure(0, weight=1)
self._refresh_items()
self.update()
self.minsize(self.winfo_reqwidth(), self.winfo_reqheight())
center_window(self)
def _refresh_items(self):
self.no_read.clear()
for l in self.labels:
self.lst.insert(tk.END, l)
def _reset_items(self):
self._refresh_items()
self.master.evaluate_data()
def _remove_item(self):
indexes = self.lst.curselection()
if not indexes: return
for i in indexes:
item = self.lst.get(i)
try:
index = self.labels.index(item)
self.no_read.append(index)
self.master.evaluate_data()
except ValueError:
return
self.lst.delete(i)
def _close(self):
self.grab_release()
self.destroy()
self.master.close_evaluate_data()
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title('PDF => CSV')
p_file = tk.Frame(self)
p_file.grid(row=0, column=0, sticky='ew')
self.bt_sel_file = tk.Button(p_file, text='Seleziona PDF',
padx=5, pady=5,
command=self._sel_file)
self.bt_sel_file.grid(row=0, column=0, sticky='ew')
self.bt_close_file = tk.Button(p_file, text='Chiudi PDF',
padx=5, pady=5,
command=self._close_file)
self.bt_close_file.grid(row=0, column=1, sticky='ew')
self.bt_make_csv = tk.Button(p_file, text='Crea CSV',
padx=5, pady=5,
command = self._make_csv)
self.bt_make_csv.grid(row=0, column=2, sticky='ew')
self.bt_close = tk.Button(p_file, text='Esci',
padx=5, pady=5,
command=self.destroy)
self.bt_close.grid(row=0, column=3, sticky='ew')
p_file.grid_columnconfigure(0, uniform=1, weight=1)
p_file.grid_columnconfigure(1, uniform=1, weight=1)
p_file.grid_columnconfigure(2, uniform=1, weight=1)
p_file.grid_columnconfigure(3, uniform=1, weight=1)
p_text = tk.Frame(self)
p_text.grid(row=1, column=0, sticky='nsew')
lbl = tk.Label(p_text, text='Righe testo estratte dal PDF',
justify='left', padx=5, pady=5, anchor='w')
lbl.grid(row=0, column=0, columnspan=3, sticky='ew')
self.pdf_text = tk.Text(p_text, height=15, bg='#D5E711',
wrap='none', padx=5, pady=5)
self.pdf_text.grid(row=1, column=0, sticky='nsew')
v_scr_1 = tk.Scrollbar(p_text, orient=tk.VERTICAL,
command=self.pdf_text.yview)
self.pdf_text.configure(yscrollcommand=v_scr_1.set)
v_scr_1.grid(row=1, column=1, sticky='ns')
h_scr_1 = tk.Scrollbar(p_text, orient=tk.HORIZONTAL,
command=self.pdf_text.xview)
self.pdf_text.configure(xscrollcommand=h_scr_1.set)
h_scr_1.grid(row=2, column=0, sticky='ew')
p_bt_file = tk.Frame(p_text)
p_bt_file.grid(row=1, column=2, sticky='ns')
lbl = tk.Label(p_bt_file, text='Car. separatore:', anchor='w',
padx=5, pady=5)
lbl.grid(row=0, column=0)
self.e_sep = tk.Entry(p_bt_file, width=3)
self.e_sep.grid(row=1, column=0)
self.bt_del_line = tk.Button(p_bt_file, text='Elimina righe',
padx=5, pady=5, command=self._del_select_rows)
self.bt_del_line.grid(row=3, column=0, sticky='nsew')
self.bt_trasf_line = tk.Button(p_bt_file, text='Trasferisci riga',
padx=5, pady=5, command=self._data_transfer)
self.bt_trasf_line.grid(row=4, column=0, sticky='nsew')
self.bt_elab_lines = tk.Button(p_bt_file, text='Elabora righe',
padx=5, pady=5, command=self._elab_rows)
self.bt_elab_lines.grid(row=5, column=0, sticky='nsew')
p_bt_file.grid_rowconfigure(2, uniform=2, weight=1)
p_bt_file.grid_rowconfigure(3, uniform=2, weight=1)
p_bt_file.grid_rowconfigure(4, uniform=2, weight=1)
p_bt_file.grid_rowconfigure(5, uniform=2, weight=1)
p_text.grid_columnconfigure(0, weight=1)
p_text.grid_rowconfigure(1, weight=1)
p_csv = tk.Frame(self)
p_csv.grid(row=2, column=0, sticky='nsew')
lbl = tk.Label(p_csv, text='Righe elaborate per il CSV',
justify='left', padx=5, pady=5, anchor='w')
lbl.grid(row=0, column=0, columnspan=3, sticky='ew')
self.csv_text = tk.Text(p_csv, height=15, bg='#E7D011',
wrap='none', padx=5, pady=5)
self.csv_text.grid(row=1, column=0, sticky='nsew')
v_scr_2 = tk.Scrollbar(p_csv, orient=tk.VERTICAL,
command=self.csv_text.yview)
self.csv_text.configure(yscrollcommand=v_scr_2.set)
v_scr_2.grid(row=1, column=1, sticky='ns')
h_scr_2 = tk.Scrollbar(p_csv, orient=tk.HORIZONTAL,
command=self.csv_text.xview)
self.csv_text.configure(xscrollcommand=h_scr_2.set)
h_scr_2.grid(row=2, column=0, sticky='ew')
p_bt_csv = tk.Frame(p_csv)
p_bt_csv.grid(row=1, column=2, sticky='ns')
self.bt_del_col = tk.Button(p_bt_csv, text='Elimina colonne...',
padx=5, pady=5, command=self._gest_columns)
self.bt_del_col.grid(row=0, column=0, sticky='ew')
self.chk_var = tk.BooleanVar()
self.chk_var.set(False)
self.chk_tab = tk.Checkbutton(p_bt_csv, text='Sostituisci con\ntabulazione',
var= self.chk_var, padx=5, pady=5, justify='left')
self.chk_tab.grid(row=1, column=0, sticky='s')
p_bt_csv.grid_rowconfigure(1, weight=1)
p_csv.grid_columnconfigure(0, weight=1)
p_csv.grid_rowconfigure(1, weight=1)
self.grid_columnconfigure(0, weight=1)
self.grid_rowconfigure(1, weight=1)
self.grid_rowconfigure(2, weight=1)
self.init_dir = os.getenv('HOME')
self._initialize()
self.update()
self.minsize(self.winfo_reqwidth(), self.winfo_reqheight())
center_window(self)
def _initialize(self):
self.e_sep.delete(0, 'end')
self.e_sep.insert(0, ';')
self.bt_sel_file.configure(state='normal')
self.bt_close_file.configure(state='disabled')
self.bt_make_csv.configure(state='disabled')
self.bt_close.configure(state='normal')
self.bt_del_line.configure(state='disabled')
self.bt_trasf_line.configure(state='disabled')
self.bt_elab_lines.configure(state='disabled')
self.pdf_text.delete('1.0', 'end')
self.pdf_text.configure(state='disabled')
self.csv_text.delete('1.0', 'end')
self.csv_text.configure(state='disabled')
self.state = ''
self.source_data = []
self.no_read = []
def _sel_file(self):
f_types =[('File pdf', '*.pdf')]
try:
f = fdlg.askopenfile(parent=self,
initialdir = self.init_dir,
title='Selezione PDF',
mode='rb',
filetypes=f_types)
lines = None
if f:
self.init_dir = os.path.dirname(f.name)
pdf = pdftotext.PDF(f)
f.close()
for i in range(len(pdf)):
lines = pdf[i].splitlines()
if lines:
self._set_data(lines)
except OSError:
msgb.showerror(title='Apertura fallita', message='Errore lettura file')
def _set_data(self, data=None):
if not data: return
self.pdf_text.configure(state='normal')
for row in data:
self.pdf_text.insert('end', row +'\n')
self.pdf_opened = True
self._evaluate_state()
def _evaluate_state(self):
if len(self.pdf_text.get('1.0', 'end-1c')) == 0:
self.bt_close_file.configure(state='disabled')
self.bt_del_line.configure(state='disabled')
self.bt_trasf_line.configure(state='disabled')
self.bt_elab_lines.configure(state='disabled')
else:
self.bt_close_file.configure(state='normal')
self.bt_del_line.configure(state='normal')
self.bt_trasf_line.configure(state='normal')
self.bt_elab_lines.configure(state='normal')
if len(self.csv_text.get('1.0', 'end-1c')) == 0:
self.bt_make_csv.configure(state='disabled')
self.bt_del_col.configure(state='disabled')
else:
self.bt_make_csv.configure(state='normal')
self.bt_del_col.configure(state='normal')
def _get_rows_intervall(self):
if self.pdf_text.tag_ranges(tk.SEL):
init_index = self.pdf_text.index(tk.SEL_FIRST)
end_index = self.pdf_text.index(tk.SEL_LAST)
else:
init_index = self.pdf_text.index(tk.INSERT)
end_index = init_index
first = int(init_index.split('.')[0])
last = int(end_index.split('.')[0])
return [x for x in range(first, last+1)]
def _del_select_rows(self):
rows = self._get_rows_intervall()
if not rows: return
rows.reverse()
for n in rows:
self.pdf_text.delete(str(n)+'.0', str(n)+'.end + 1 char')
self._evaluate_state()
def _data_transfer(self):
current = self.pdf_text.index(tk.INSERT)
row = current.split('.')[0]
text = self.pdf_text.get(row + '.0', row + '.end')
self.csv_text.configure(state='normal')
self.csv_text.insert('end', text +'\n')
self.csv_text.configure(state='disabled')
self.pdf_text.delete(row + '.0', row + '.end + 1 char')
self._evaluate_state()
def _gest_columns(self):
self.state = 'remove_data'
self.source_data = self.csv_text.get('1.0', 'end').split('\n')
text = self.csv_text.get('1.0', '1.end')
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
labels = text.split(sep)
dlg = SetNoRead(self, labels, self.no_read)
dlg.grab_set()
def _elab_rows(self):
rows = self._get_rows_intervall()
if not rows: return
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
self.csv_text.configure(state='normal')
for n in rows:
text = self.pdf_text.get(str(n)+'.0', str(n)+'.end')
words = text.split()
text = sep.join(words)
self.csv_text.insert('end', text +'\n')
self.csv_text.configure(state='disabled')
rows.reverse()
for n in rows:
self.pdf_text.delete(str(n)+'.0', str(n)+'.end + 1 char')
self._evaluate_state()
def evaluate_data(self):
self.csv_text.configure(state='normal')
if not self.source_data: return
self.csv_text.delete('1.0', 'end')
if not self.no_read:
for row in self.source_data:
self.csv_text.insert('end', row + '\n')
else:
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
for row in self.source_data:
items = row.split(sep)
data_view = []
for i in range(len(items)):
if not i in self.no_read:
data_view.append(items[i])
text = sep.join(data_view)
self.csv_text.insert('end', text + '\n')
self.csv_text.configure(state='disabled')
def close_evaluate_data(self):
self.evaluate_data()
self.source_data = []
self.state = ''
def _close_file(self):
self._initialize()
def _make_csv(self):
f_types = [('Comma separed values', '*.csv')]
f_name = fdlg.asksaveasfilename(parent=self,
initialdir = self.init_dir,
title='Creazione CSV',
confirmoverwrite=False,
filetypes=f_types)
if not f_name: return
self.csv_text.configure(state='normal')
text = self.csv_text.get('1.0', 'end-1c')
if self.chk_var.get():
sep = self.e_sep.get()
text = text.replace(sep, '\U00000009')
try:
with open(f_name, 'w') as f:
f.write(text)
except OSError:
msgb.showerror(title='Generazione fallita',
message='Errore scrittura file')
return
self.csv_text.delete('1.0', 'end')
self.csv_text.configure(state='disabled')
self._evaluate_state()
# ****************************
# *** FUNZIONI DI SERVIZIO ***
# ****************************
def center_window(gui):
''' Centra una finestra, passata come parametro, sullo schermo '''
l = gui.winfo_screenwidth()
a = gui.winfo_screenheight()
wx = gui.winfo_reqwidth()
wy = gui.winfo_reqheight()
gui.geometry('{}x{}+{}+{}'.format(wx, wy, (l-wx)//2, (a-wy)//2))
# ****************************
# *** LANCIO APPLICAZIONE ***
# ****************************
if __name__ == '__main__':
app = App()
app.mainloop() |



