Allora, come accennato in precedenza, la documentazione di odfpy mi ha letteralmente fatto piangere, c'è giusto qualche esempietto nel file sulle API messo in link nel precedente post ed una sezione "doc", nel master indicato, in formato html e LaTeX.
... Purtroppo, la documentazione in html non è altro che una serie di files generati automaticamente dai sorgenti, che dicono ben poco. Prendiamo, ad esempio, la docs per TableRow (una riga di tabella) molto utilizzata nell'esempio che seguirà, consultando detta documentazione troveremo :
nient'altro che un cenno alla definizione che rimanda direttamente al codice; un ermetico

Insomma, siamo un po' fregati da questo punto di vista, tutto si riduce a due righe di codice che non dicono niente, non conoscendo il dizionario dei parametri.
Ho provato anche a compilarmi la documentazione in LaTeX solo per scoprire che il documento risultante non è altro che la docs html resa pdf.
Veniamo un po' al problema che mi son posto per questa seconda categoria di template da realizzare, ossia una rappresentazione tabellare di dati con
un numero di righe necessariamente variabili.
Ora, quella variabilità del numero di righe
non ci permette di definire aprioristicamente delle variabili utente, che sono di natura fissa, ma costringe ad una costruzione "dinamica" del documento, almeno parziale.
Quindi, si hanno due possibili vie :
- Costruirsi il documento ex-novo
- Modificare un documento predisposto
reperita un po' di documentazione in giro,
tipo questa, mi son reso conto che a darci dentro, coi tempi che mi consentono lavoro e vita (grama la vita di un aspirante programmatore amatoriale) in un paio d'anni forse qualche risultato l'avrei ottenuto ma non mi sarebbe servito a molto dato che, si spera, sarò in pensione.
Ho scelto di provare una ibridazione della seconda via con il primo metodo del precedente post, ossia di impostare un template con variabili utente per i dati fissi ed una tabella predisposta con delle righe di intestazione e riepilogative finali ed una sola riga per dati, quindi tentare di modificare la sola tabella inserendo/modificando le sole righe dati.
Uno sporco trucco da vecchio programmatore VB, in sostanza, un "qualcosa" che, probabilmente, farebbe inorridire i programmatori "seri" ed i puristi ... che però ha funzionato

... oddio, non al primo colpo a dire il vero, in un primo momento, dato che i files "*.odt" sono essenzialmente una serie di XML zippati, ho provato, senza successo, a decomprimere, individuare e replicare aggiornata la riga dati predisposta e ricomprimere ... senza successo, troppo intricate le relazioni tra gli xml ed il documento non veniva più riconosciuto.
Metodo 2 : Modifica di un template
San google mi ha permesso di rintracciare come "copiare" un elemento componente un documento di testo e la valutazione degli xml (con anche un po' di "tirare ad indovinare") mi ha fatto rintracciare gli elementi chiave componenti una tabella, infine, qualche tentativo per prova/errore le caratteristiche da replicare ... ora espongo l'insieme.
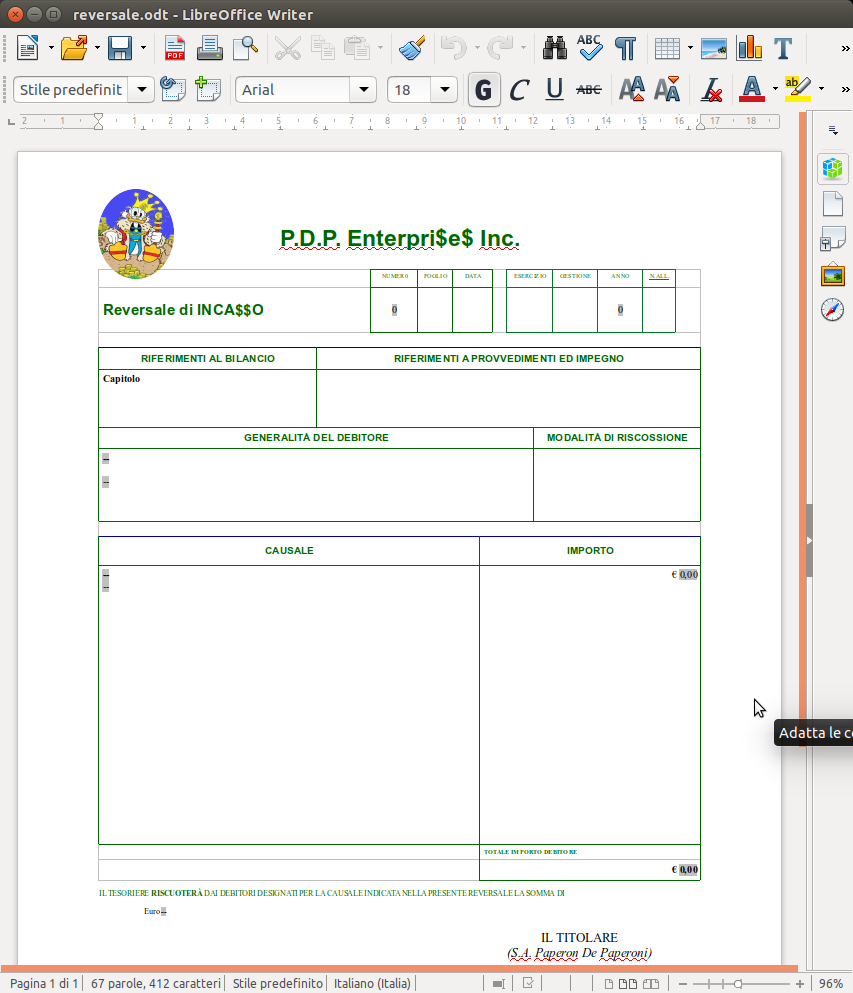
Posto un documento di riferimento così composto:
Dopo averla definita, e magari formattata, daremo un
nome alla tabella, con "
Tabella -> Proprieta ..." tab "
Tabella" campo "
nome", nel caso in esempio "lista_mandati"
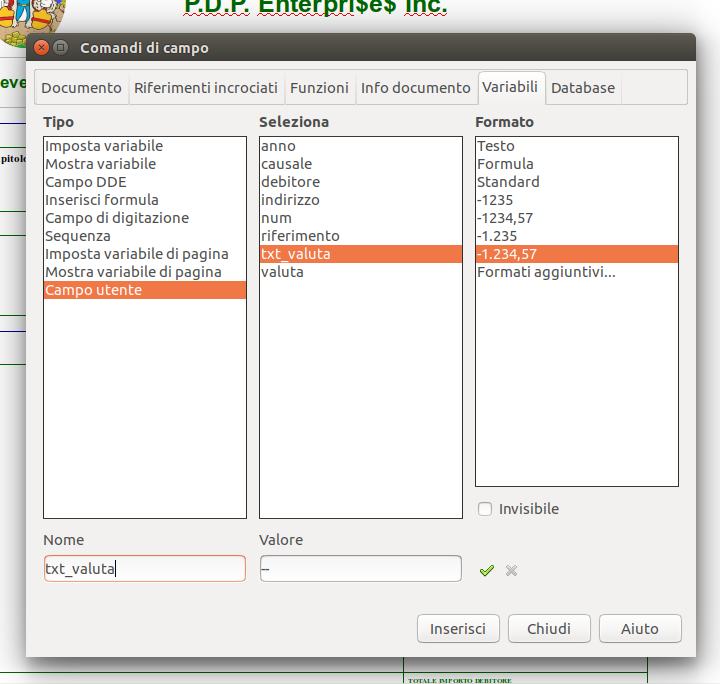
Inseriremo anche le variabili utente da impostare tramite codice come già visto, nell'esempio una sola : "anno"
Quindi salveremo il nostro "template"
2.1 : apertura del template
sempre tramite la libreria "
odfpy", già utilizzata nel primo post si potrà aprire aprire il template prodotto e modificarlo per quindi salvarlo con altro nome, per aprirlo dovremo utilizzare la funzione "
load(nome_template)" del modulo "
opendocument" della libreria, che ci restituirà un oggetto "
OpenDocument"
CODICE
>>> from odf import opendocument as od
>>> template_doc = 'templates/lst_mandati.odt'
>>> orig_doc = od.load(template_doc)
>>> type(orig_doc)
<class 'odf.opendocument.OpenDocument'>
>>>
i metodi disponibili in tale classe (un parser xml, come praticamente tutti gli oggetti odfpy, se ho capito bene) ci permetteranno di navigare tra gli elementi costituenti il nostro template, di manipolarli ed inserirne di nuovi per quindi salvare il docunento modificato tramite il metodo "
write()" di OpenDocument, nel codice di esempio alla fine del post sarà un file intermedio, cui applicare i metodi del primo post per i campi utente relativi a variabili fisse.
2.2 : Copia della tabella
Pur essendo fattibile modificare direttamente la tabella presente nel template, ho preferito procedere definendone una nuova e copiando gli elementi utili di quella di riferimento, ciò per la maggiore linearità che il metodo comporta.
In primo luogo, è necessario individuare, tra gli elementi costituenti il documento, la tabella di riferimento, per far ciò estrarremo dal documento tutti gli elementi di tipo "
table.Table" tramite il metodo "
getElementsByType()" di OpenDocument, quindi, per ogni eventuale oggetto verificheremo tramite la funzione bult-in "
hasattr()" se ha degli attributi definiti e se tra questi vi sia un attributo "
name" uguale a quello prima impostato per la nostra tabella di riferimento, se lo troviamo, viene memorizzata la tabella che lo contiene quale riferimento, altrimenti il processo viene interrotto.
ne codice di esempio, ciò è effettuato nella funzione "
edit_table", questo è lo stralcio di codice relativo :
CODICE
all_table = doc.getElementsByType(table.Table)
for xt in all_table:
if hasattr(xt, 'attributes'):
tbl_name = xt.getAttribute('name')
if tbl_name == table_name:
e_table = xt
break
if e_table is None:
print('Template tabella non trovato')
return
2.2.1 : Parti logiche
Pur essendo le tabelle di un documento odt fondamentalmente strutturate in modo analogo ad una tabella html, nell'esempio in questione (ed anche nel comune operare) si è impostato tutto con normali righe, delle quali due rappresentano una sorta di "intestazione", una è una specie di "piede" e solo una, la terza, rappresenta lo spazio dedicato ai dati da elencare.
In merito alla "costituzione" di una riga di tabella, essa contiene delle "celle" che a loro volta contengono almeno uno o più Paragrafi.
Ognuno di tali elementi ha diverse proprietà associate, in merito ai paragrafi, la proprietà che fondamentalmente interessa è lo stile da applicare al testo che inseriremo, ossia la proprietà "
stylename".
Per le celle non è così semplice dato che possono anche estendersi per più colonne o righe od anche far parte di una suddivisione di celle andando, di fatto, a costituire una matrice di celle interna ad una cella. Dopo vari "tentativi" ho individuato, oltre lo stylename, le proprietà "
numbercolumnsspanned", "
numberrowsspanned", "
numbermatrixcolumnsspanned" e "
numbermatrixrowsspanned" il minimo sindacale da leggersi (capito mo a che servono 'sti appunti?)
Pertanto, memorizziamo quali variabili locali a edit_table() le celle della terza riga ed i stylename di ogni primo paragrafo di ogni cella, per usarli in seguito
CODICE
# estrae la lista delle righe della tabella, la terza è da duplicare
t_rows = e_table.getElementsByType(table.TableRow)
if t_rows:
tr = t_rows[2]
else:
return
# memorizza le celle originarie della riga
cells = tr.getElementsByType(table.TableCell)
# e gli stili di paragrafo
parag_style_names = []
for i in range(len(cells)):
style_name = cells[i].getAttribute('stylename')
par = cells[i].getElementsByType(text.P)
style_name = par[0].getAttribute('stylename')
parag_style_names.append(style_name)
Quindi procediamo a crearci una nuova tabella, magari assegnandoli un nome diverso da quello della "sorgente" :
CODICE
# crea la tabella di destinazione
d_table = table.Table(name='Elenco_mandati')
Ora è bene procedere ordinatamente, la prima cosa da farsi è replicare nella tabella di destinazione la struttura delle singole colonne componenti da tabella di template, per farlo dovremo creare nuovi oggetti TableColumn in cui replicare le impostazioni delle colonne originarie e, quindi assegnarli alla nuova tabella
CODICE
# rileva le colonne della tabella originale
cols = t_table.getElementsByType(table.TableColumn)
# cicla le colonne copiandone gli stili
for col in cols:
n_col = table.TableColumn()
n_col.setAttribute('stylename', col.getAttribute('stylename'))
d_table.addElement(n_col)
ovvio,
d_table è la tabella di destinazione e
t_table quella di template.
Qundi dovremo creare nuovi oggetti TableRow corrispondenti alle righe da copiare, e per ognuno di essi tanti oggetti TableCell quante sono le celle costituenti ogni singola riga e tanti oggetti text.P (paragrafi) quanti sono i paragrafi presenti in ogni singola cella.
Per tutti i nuovi oggetti dovremo replicare le proprietà interessanti degli analoghi oggetti originali, potremo far ciò utilizzando i metodi "
getAttribute(attributo)" e "
setAttribute(attributo)" sui vari oggetti.
Di seguito il codice per replicare le righe di intestazione, dalla funzione "copy_headers"
CODICE
# rileva le righe della tabella originale e ne copia le prime num
rows = t_table.getElementsByType(table.TableRow)
rows = rows[:num]
# cicla le righe copiando i contenuti
for row in rows:
# crea una riga
n_row = table.TableRow()
# rileva le celle della riga originale
cells = row.getElementsByType(table.TableCell)
# cicla tra le celle copiando stili e contenuti
for cell in cells:
# crea una cella
n_cell = table.TableCell()
# copia gli attributi originali
n_cell.setAttribute('stylename', cell.getAttribute('stylename')) # stile
n_cell.setAttribute('numbercolumnsspanned',
cell.getAttribute('numbercolumnsspanned')) # estensione
n_cell.setAttribute('numberrowsspanned',
cell.getAttribute('numberrowsspanned'))
n_cell.setAttribute('numbermatrixcolumnsspanned',
cell.getAttribute('numbermatrixcolumnsspanned'))
n_cell.setAttribute('numbermatrixrowsspanned',
cell.getAttribute('numbermatrixrowsspanned'))
# rileva i paragrafi nella cella
parags = cell.getElementsByType(text.P)
# cicla tra i paragrafi copiando stile e contenuti
for p in parags:
# copia il testo
c_text = teletype.extractText(p)
# crea un nuovo paragrafo
n_p = text.P(text=c_text)
# copia lo stile
n_p.setAttribute('stylename', p.getAttribute('stylename'))
# aggiunge il paragrafo alla nuova cella
n_cell.addElement(n_p)
# aggiunge la nuova cella alla nuova riga
n_row.addElement(n_cell)
# aggiunge la nuova riga alla nuova tabella
d_table.addElement(n_row)
Un po' lunghetta vero? Tale metodologia, con qualche variante, la ho applicata diffusamente tanto nella creazione delle righe dati, derivando le proprietà delle di riferimento celle e dagli stili di paragrafo memorizzati, quanto per il "piede" della tabella, derivandoli dall'ultima riga del template.
Copiate "le intestazioni" passeremo a "popolare" la tabella con i pertineti dati .
In questo esempio di test ho utilizzato una lista di liste ma, ovviamente, nella reltà sarebbe una elaborazione a produrre qualcosa di analogo.
Per popolare le "righe dati", come già accennato, non faremo altro che creare una nuova riga di tabella per ogni riga dati da inserire, definire una cella applicando gli stili orininali della 3
a riga della tabella di riferimento ed applicarci un nuovo paragrafo con applicato il corrispondente stile quindi, se il dato con lo stesso indice (celle e dati devono essere coordinati) è da rappresentare assegnarne il valore quale testo con la istruzione "
new_P.addText(text=testo)", quindi aggiungere la riga alla nuova tabella.
Stesso discorso per il piede, effettuato nella funzione "edit_footer", che utilizzerà l'ultima riga della tabella di template quale fonte delle proprietà da applicare.
Particolari banali, è che nel "piede" viene esposta una somma di importi e che gli importi subiscono un "trattamento" particolare di formattazione, non essendo di mio gradimento la resa di "locale" per la valuta italiana.
2.3 : Sostituzione della tabella di template
Una volta completata la definizione del footer della nuova tabella dovremo inserire la tabella creata nel documento, il posto in cui inserirla è quello della tabella di riferimento ... per farlo dovremo utilizzare due passaggi, il primo
CODICE
# aggiunge la nuova tabella al documento
e_table.parentNode.insertBefore(d_table, e_table)
lo faremo direttamente dalla tabella di template che chiederà al nodo superiore di appartenenza (sarebbe il documento ma parliamo sempre di xml) di inserire la nuova tabella prima di se stessa.
Il secondo passo lo faremo dalla nuova tabella
CODICE
# ed elimina la "vecchia"
d_table.parentNode.removeChild(e_table)
che chiederà al nodo superiore di appartenenza la rimozione della "vecchia tabella"
non rimane altro che chiedere al dumento originario di creare il documento di destinazione con le modifiche apportate (punto intermedio, ve lo ricordo) e, infine, applicare i metodi del primo post per i campi utente fissi.
Un po' lunghetto, vero? non troppo poi, solo 276 righe di codice commenti compresi
CODICE
# -*- coding: utf-8 -*-
from odf import opendocument as od
from odf import table, text, teletype
from odf.element import Text
from odf.text import P
from odf import userfield as uf
import sys
import os
# definizione dei valori da inserire nel template
values = {}
values['anno'] = 2019
values['totale'] = 0.0
# definizione righe dati tabella
rows_value = [[None, 1, 1, None, 150000.0, None],
[None, 2, 2, None, 180000.0, None],
[None, 3, None, None, 48741.90, 'D.D.S. 075/16 - 2019'],
[None, 4, 3, None, 463537.26, 'retribuzioni'],
[None, 5, 4, None, 91545.73, None],
[None, 6, 5, None, 41589.8, None],
[None, 7, 6, None, 382289.15, 'regolarizzazione provvisorio'],
[None, 8, 7, None, 31768.8, None],
[None, 9, 8, None, 430976.92, None],
[None, 10, 9, None, 719914.0, 'retribuzioni'],
[None, 11, 10, None, 108478.08, None],
[None, 12, None, None, 500000, 'Delibera 344/2019'],
[None, 13, 11, None, 130000.0, None],
[None, 14, 14, None, 96295.0, 'Delibera 30/2019'],
[None, 15, 15, None, 515000.0, 'Determina 25/2019'],
[None, 16, None, None, 4.0, 'regolazione provvisori n.ri 2 e 7']
]
def italy_currency(str_num):
'''
Converte una stringa tappresentante una float in una stringa trappresentante
un numero in notazione italiana (punto per sep. migliaia, virgola sep. decimali)
'''
parts = str_num.split('.')
blocks = len(parts[0]) // 3
lista = [x for x in parts[0]]
sub_num = []
while len(lista) > 3:
sub = lista[-3:]
sub_num.append(sub)
lista = lista[:-3]
sub_num.append(lista)
sub_num.reverse()
sub_num = [''.join(x) for x in sub_num]
return '.'.join(sub_num) + ',' + parts[1]
def copy_headers(t_table, d_table, num):
'''
Copia le prime "num" righe della tabella di riferimento.
Parametri :
--- t_table --- tabella di riferimento
--- d_table --- tabella di destinazione
--- num --- numero delle righe da copiare
'''
# rileva le colonne della tabella originale
cols = t_table.getElementsByType(table.TableColumn)
# cicla le colonne copiandone gli stili
for col in cols:
n_col = table.TableColumn()
n_col.setAttribute('stylename', col.getAttribute('stylename'))
d_table.addElement(n_col)
# rileva le righe della tabella originale e ne copia le prime num
rows = t_table.getElementsByType(table.TableRow)
rows = rows[:num]
# cicla le righe copiando i contenuti
for row in rows:
# crea una riga
n_row = table.TableRow()
# rileva le celle della riga originale
cells = row.getElementsByType(table.TableCell)
# cicla tra le celle copiando stili e contenuti
for cell in cells:
# crea una cella
n_cell = table.TableCell()
# copia gli attributi originali
n_cell.setAttribute('stylename', cell.getAttribute('stylename')) # stile
n_cell.setAttribute('numbercolumnsspanned',
cell.getAttribute('numbercolumnsspanned')) # estensione
n_cell.setAttribute('numberrowsspanned',
cell.getAttribute('numberrowsspanned'))
n_cell.setAttribute('numbermatrixcolumnsspanned',
cell.getAttribute('numbermatrixcolumnsspanned'))
n_cell.setAttribute('numbermatrixrowsspanned',
cell.getAttribute('numbermatrixrowsspanned'))
# rileva i paragrafi nella cella
parags = cell.getElementsByType(text.P)
# cicla tra i paragrafi copiando stile e contenuti
for p in parags:
# copia il testo
c_text = teletype.extractText(p)
# crea un nuovo paragrafo
n_p = text.P(text=c_text)
# copia lo stile
n_p.setAttribute('stylename', p.getAttribute('stylename'))
# aggiunge il paragrafo alla nuova cella
n_cell.addElement(n_p)
# aggiunge la nuova cella alla nuova riga
n_row.addElement(n_cell)
# aggiunge la nuova riga alla nuova tabella
d_table.addElement(n_row)
def edit_footer(t_table, d_table, dida, summa):
# rileva l'ultima riga della tabella di origine
t_rows = t_table.getElementsByType(table.TableRow)
if t_rows:
tr = t_rows[-1]
else:
return
# memorizza la celle originarie della rigaper riferimento
cells = tr.getElementsByType(table.TableCell)
# crea una nuova riga
n_t_row = table.TableRow()
# crea una nuova cella e copia le impostazioni della prima cella
# della riga di riferimento
n_cell = table.TableCell()
n_cell.setAttribute('stylename', cells[0].getAttribute('stylename')) # stile
n_cell.setAttribute('numbercolumnsspanned',
cells[0].getAttribute('numbercolumnsspanned')) # estensione
n_cell.setAttribute('numberrowsspanned',
cells[0].getAttribute('numberrowsspanned'))
n_cell.setAttribute('numbermatrixcolumnsspanned',
cells[0].getAttribute('numbermatrixcolumnsspanned'))
n_cell.setAttribute('numbermatrixrowsspanned',
cells[0].getAttribute('numbermatrixrowsspanned'))
# estrae i paragrafi della cella origine e copia lo stile del primo
par = cells[0].getElementsByType(text.P)
style_name = par[0].getAttribute('stylename')
# crea un nuovo paragrafo, scrive la didscalia e la assegna alla nuva riga
new_P = text.P()
new_P.setAttribute('stylename', style_name)
new_P.addText(text=dida)
# aggiunge il paragrafo alla nuova cella
n_cell.addElement(new_P)
# aggiunge la cella alla nuova riga
n_t_row.addElement(n_cell)
# crea una nuova cella e copia le impostazioni della seconda cella
# della riga di riferimento
n_cell = table.TableCell()
n_cell.setAttribute('stylename', cells[1].getAttribute('stylename')) # stile
n_cell.setAttribute('numbercolumnsspanned',
cells[1].getAttribute('numbercolumnsspanned')) # estensione
n_cell.setAttribute('numberrowsspanned',
cells[1].getAttribute('numberrowsspanned'))
n_cell.setAttribute('numbermatrixcolumnsspanned',
cells[1].getAttribute('numbermatrixcolumnsspanned'))
n_cell.setAttribute('numbermatrixrowsspanned',
cells[1].getAttribute('numbermatrixrowsspanned'))
# estrae i paragrafi della cella origine e copia lo stile del primo
par = cells[1].getElementsByType(text.P)
style_name = par[0].getAttribute('stylename')
# crea un nuovo paragrafo, scrive la didscalia e la assegna alla nuva riga
new_P = text.P()
new_P.setAttribute('stylename', style_name)
testo= '%.2f' % summa
testo = italy_currency(testo)
new_P.addText(text=testo)
# aggiunge il paragrafo alla nuova cella
n_cell.addElement(new_P)
# aggiunge la cella alla nuova riga
n_t_row.addElement(n_cell)
# aggiunge la riga alla nuova tabella
d_table.addElement(n_t_row)
def edit_table(doc, table_name):
'''
Crea una nuova tabella, sulla base di un'altra di riferimento, per
poi sostituire il riferimento con la nuova definita.
Parametri :
--- doc --- documento da manipolare
--- table_name --- nome tabella di riferimento
'''
all_table = doc.getElementsByType(table.Table)
for xt in all_table:
if hasattr(xt, 'attributes'):
tbl_name = xt.getAttribute('name')
if tbl_name == table_name:
e_table = xt
break
if e_table is None:
print('Template tabella non trovato')
return
# estrae la lista delle righe della tabella, la terza è da duplicare
t_rows = e_table.getElementsByType(table.TableRow)
if t_rows:
tr = t_rows[2]
else:
return
# memorizza le celle originarie della riga
cells = tr.getElementsByType(table.TableCell)
# e gli stili di paragrafo
parag_style_names = []
for i in range(len(cells)):
style_name = cells[i].getAttribute('stylename')
par = cells[i].getElementsByType(text.P)
style_name = par[0].getAttribute('stylename')
parag_style_names.append(style_name)
# crea la tabella di destinazione
d_table = table.Table(name='Elenco_mandati')
copy_headers(e_table, d_table, 2)
# per ogni riga di dati crea una riga nella nuova tabella
summa = 0.0
for riga in rows_value:
summa += riga[4]
# "sistema" la riga dati da visualizzare
data_row = riga[:4] + [summa] + riga[4:]
# crea una nuova riga
n_t_row = table.TableRow()
# per ogni elemento dati crea una cella ed eventualmente un paragrafo
for i in range(len(data_row)):
n_cell = table.TableCell()
# copia gli attributi originali
n_cell.setAttribute('stylename', cells[i].getAttribute('stylename')) # stile
n_cell.setAttribute('numbercolumnsspanned',
cells[i].getAttribute('numbercolumnsspanned')) # estensione
n_cell.setAttribute('numberrowsspanned',
cells[i].getAttribute('numberrowsspanned'))
n_cell.setAttribute('numbermatrixcolumnsspanned',
cells[i].getAttribute('numbermatrixcolumnsspanned'))
n_cell.setAttribute('numbermatrixrowsspanned',
cells[i].getAttribute('numbermatrixrowsspanned'))
#n_cell.setAttribute('stylename', cells_style_names[i])
# se l'elemento è valido definisce un paragrafo
if data_row[i]:
new_P = text.P()
new_P.setAttribute('stylename', parag_style_names[i])
if type(data_row[i]) == float:
testo= '%.2f' % data_row[i]
testo = italy_currency(testo)
else:
testo = data_row[i]
new_P.addText(text=testo)
# aggiunge il paragrafo alla nuova cella
n_cell.addElement(new_P)
# aggiunge la cella alla nuova riga
n_t_row.addElement(n_cell)
# aggiunge la riga alla nuova tabella
d_table.addElement(n_t_row)
# scrive il riepilogo delle somme (inutile ma lo vogliono)
dida = "Sommano i mandati"
edit_footer(e_table, d_table, dida, summa)
# aggiunge la nuova tabella al documento
e_table.parentNode.insertBefore(d_table, e_table)
# ed elimina la "vecchia"
d_table.parentNode.removeChild(e_table)
template_doc = os.path.join(os.path.abspath(os.path.dirname(sys.argv[0])),
'templates/lst_mandati.odt')
dest_doc = os.path.join(os.path.abspath(os.path.dirname(sys.argv[0])),
'documents/test_lst_mandati.odt')
table_name = 'lista_mandati'
orig_doc = od.load(template_doc)
edit_table(orig_doc, table_name)
orig_doc.write(dest_doc)
# ciliegina, compilare i campi utente anno
values = {}
values['anno'] = 2019
doc_fin = os.path.join(os.path.abspath(os.path.dirname(sys.argv[0])),
'documents/lista_mandati.odt')
us_f = uf.UserFields(src=dest_doc, dest=doc_fin)
us_f.update(values)
us_f.savedoc()
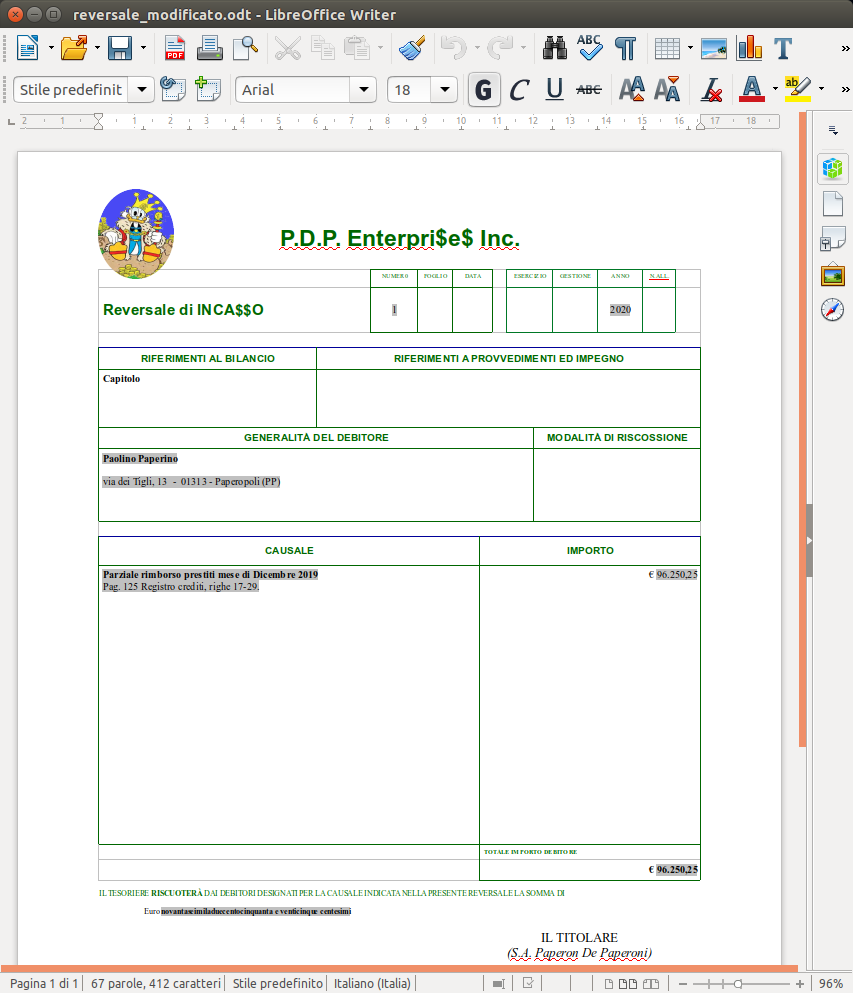
che partendo dal documento su riportato, produrranno questo :
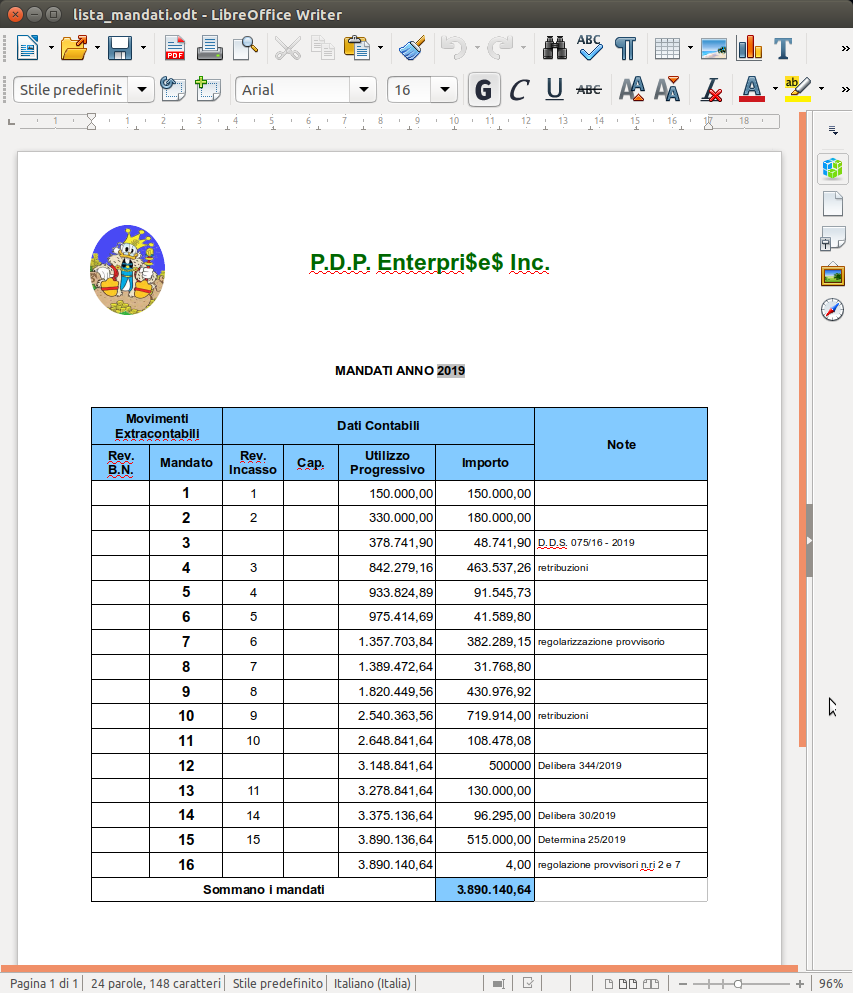
Tutto sommato un "costo" modesto per produrre un report modificabile formattato discretamente bene.
Certo, sono stati evitati tutta una serie di "accorgimenti pratici" (gestione degli errori, etc) e si potrebbe anche creare direttamente il documento finale ma, diciamocelo, se si può fare a meno inutile complicarsi la vita

Ciao
Edited by nuzzopippo - 29/2/2020, 18:13


 il mondo è quello che è) da vari uffici e soggetti, ognuno per le proprie specifiche competenze sulla base di "modelli di documento" stabiliti anni fa ed i cui template ho provveduto io stesso (pur se la faccenda non mi riguarda) ad impostare per i formati *.odt ed *.ods (rispettivamente, writer e calc di Libreoffice/Openoffice).
il mondo è quello che è) da vari uffici e soggetti, ognuno per le proprie specifiche competenze sulla base di "modelli di documento" stabiliti anni fa ed i cui template ho provveduto io stesso (pur se la faccenda non mi riguarda) ad impostare per i formati *.odt ed *.ods (rispettivamente, writer e calc di Libreoffice/Openoffice).