TextUtility - 2a parte
Riprendiamo il post da dove l'avevamo lasciato, cioè ai metodi di utilizzo di quanto realizzato più coerenti con le impostazioni dati, che abbiamo visto sintetizzata nella tabella di controlli ed uso precedente (un paio sono stati omessi, vedremo poi).
Dal post sul viewer abbiamo visto che, a discrezione dell'utilizzatore, può essere estratto il testo da una o più pagine alla volta e da più documenti in successione aggiungendolo al contenuto del controllo
self.pdf_text, di una istanza formato "
text" di TextUtility, editato e salvato, oppure manipolato per produrre dati in formato CSV.
La prima casistica (salvataggio testo) è decisamente banale, l'utente carica il testo che gli serve, con operazioni di edithing ordinario cancella eventuali parti non interessanti, corregge eventuali svarioni quindi lo salva come testo, oppure seleziona le parti interessanti per copiarle con i comandi del sistema in uso per poiincollarli nel word-processor preferito, e chiude li ... metodologia presumibilmente utile per estrazioni OCR, i PDF non da immagini permettono di farlo direttamente.
... Non è detto sia così banale organizzare i dati derivanti dall'estrazione di testo di uno o più file pdf in quelle tabelle "piatte" che caratterizzano la codifica CSV, tali tabelle, per essere lette, devono avere un numero di campi costante, con magari una intestazione, una estrazione OCR è certo che non darà tale "costanza", inoltre, dato l'alto numero di "spurie" che si ottengo è inadatta a tale compito, salvo casi eccezionali, ma anche parlando di "estrazione diretta" del testo (con
pdftotext per ora) detta "costanza" non è garantita per niente: la lunghezza del testo si fermerà all'ultimo dato utile, con conseguenti possibili problemi di indicizzazione in fase di "lettura dati", inoltre gli allineamenti, tanto per riga quanto per colonna, non sempre sono perfettamente coerenti.
Pertanto, la prima operazione da effettuare è l'estrazione del testo da trattare, magari con contestuale eliminazione delle parti di testo ridondanti, tipo intestazione di colonna ripeture su varie pagine, eliminazione di righe testo non pertinenti ai dati, etc., solo dopo aver ottenuto il testo che si vuol effettivamente trattare dare avvio al una sessione di definizione dei dati csv premendo il pulsante "
Attiva CSV" (ovvero
self.bt_edit) nel cui callback (
_on_edit(self)) verrà avviata una ulteriore istanza di TextUtility di tipo "csv", memorizzata nella variabile di istanza "self.csv_win"
*, verificato che il corrente carattere separatore non sia presente nel testo, in tal caso si ricerà un warning, ed elaborato il testo presente in
self.pdf_text valutando il numero di caratteri
* presenti nella riga di testo più lunga ed aggiungendo degli spazi alle altre righe in modo che raggiungano la stessa dimensione.
* In questo prototipo non si è sottilizzato a equilibrare completamente il codice con accorgimenti quali verificare l'esistenza di self.csv_win al momento del trasferimento dati, ovvero ricalibrazione del testo ad eventuali aggiunte successive all'avvio di una sessione di definizione dati. Accorgimenti facilmente implementabili ma ridondanti per un semplice prototipo.Una volta estratto il testo che vogliamo trattare, il "cosa fare" dipenderà tanto dal nostro obiettivo quanto dalla "qualità" di ciò che abbiamo ottenuto, se tutto ciò che vogliamo è "ottenere" quel testo ci sarà sufficiente salvarlo, direttamente o dopo qualche correzione di eventuali spurie (lo OCR ne da). Se, invece, ciò che vogliamo è definire il testo estratto quale "dati", da inserire in un foglio elettronico, database o altro, apriremo la nostra sessione di definizione dati, le caratteristiche del testo estratto ci forniranno due possibili vie di approccio.
La via "Facile"
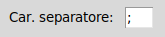
In molte circostanze, probabilmente, ci si troverà a voler estrarre blocchi di dati numerici separati tra loro da spazi, magari con spazi interni presenti solo in una riga di intestazione, o neanche. In tal caso, è prevista una forma semplificata di elaborazione, all'occorrenza può essere editata la riga rappresentante l'intestazione eliminando gli spazi eccedenti ed inserendo il carattere di separazione campo stabilito
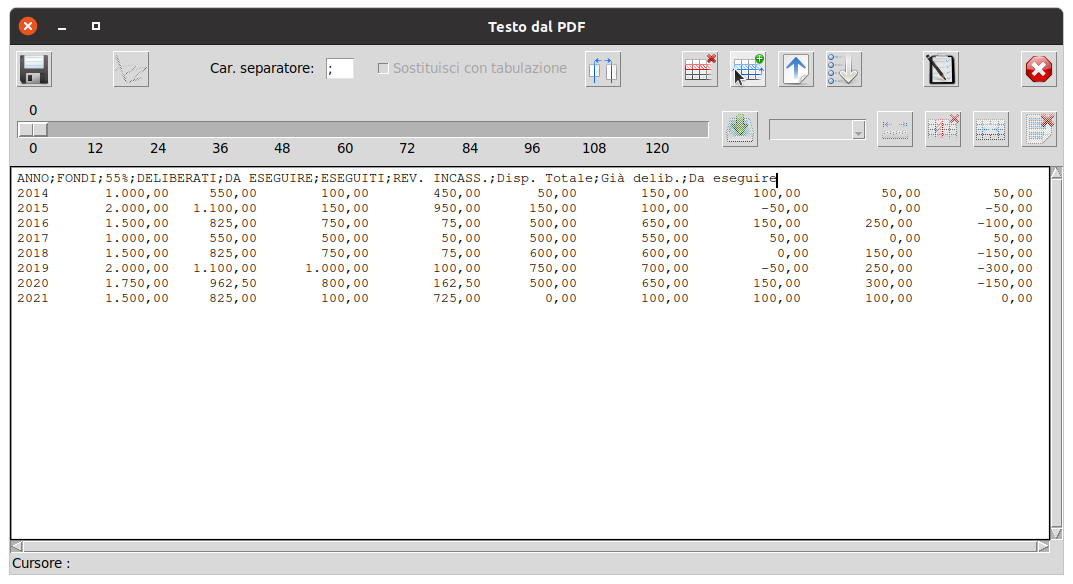
quindi premere il pulsante "Trasferisci Righe", la riga di intestazione verrà inviata "così com'é" alla finestra per il csv ed eliminata dalla casella di testo di definizione.
A questo punto non resta altro da fare che selezionare l'insieme di righe da elaborare quali dati CSV
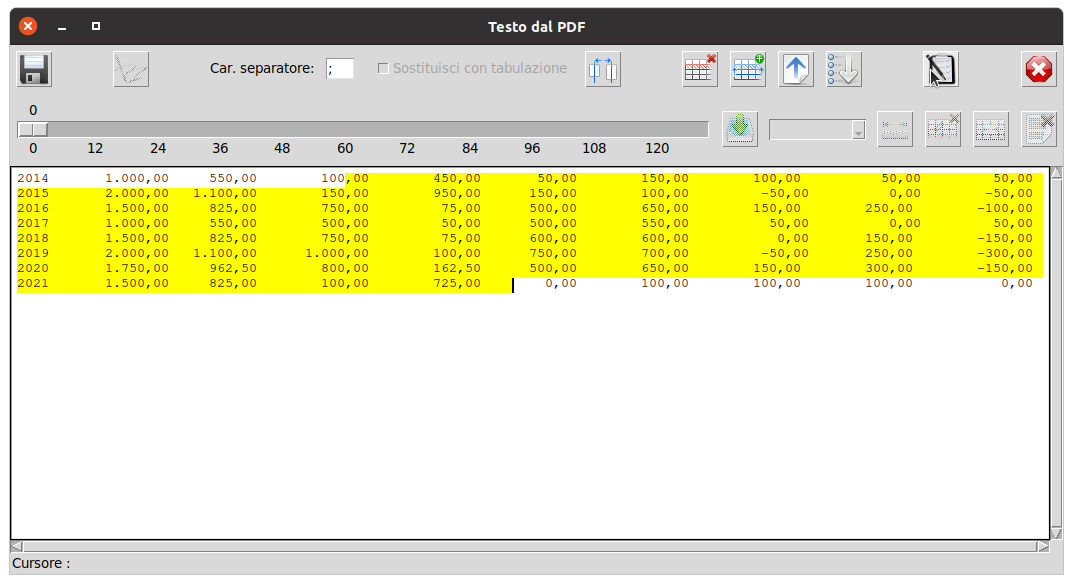
e premere il pulsante "
Elabora CSV", il callback relativo valuterà la variabile di stato "
self.defcol" che memorizza la condizione di attivazione della definizione di colonne dati e, non trovandola attiva, invocherà il metodo di classe "
self._elab_minor()" che elaborerà ed eliminerà le righe selezionate dall'indice maggiore al minore, per poi trasferire il tutto alla finestra per il csv
CODICE
def _make_csv(self):
try:
self._verify_sep()
except ValueError as e:
message = 'Errore separatore : {0}'.format(e)
msg = mydialog.Message(self).show_error(message,
title='Separatore incongruo')
mydialog.center_win(msg)
return
sep = self.e_sep.get()
self.csv_win.set_separator(sep)
if not self.defcol:
self._elab_minor()
else:
self._elab_major()
...
def _elab_minor(self):
if self.csv_win == None or not self.csv_win.winfo_exists():
return
rows = self._get_rows_intervall()
if not rows: return
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
for n in rows:
text = self.pdf_text.get(str(n)+'.0', str(n)+'.end')
words = text.split()
text = sep.join(words)
self.csv_win.add_text(text)
rows.reverse()
for n in rows:
self.pdf_text.delete(str(n)+'.0', str(n)+'.end + 1 char')
Tale elaborazione leggerà le singole righe di testo selezionare estraendone le singole "parole" con le quali produrrà una nuova stringa unendo dette "parole" tramite il separatore, la stringa prodotta verrà inviata alla finestra per il CSV quale aggiunta, alla fine le righe di testo elaborate verranno eliminate, partendo da quella di indice maggiore.
La procedura può essere effettuata in più "fasi", una volta completata non resterà altro da fare che salvare i dati dalla finestra del CSV.
... Da notare che nel callback ("
_make_csv(self)") viene nuovamente verificata la eventuale presenza del carattere separatore nel testo (TUTTO il testo), questa volta, però, non vi sarà un avvertimento ma un messaggio di errore : o si cambia il carattere di separazione (ovvero lo si elimina dal testo) o i dati non verranno processati.
Ok : complichiamoci la vita!
Non necessariamente i dati da estrarre sono "ragionevoli", nel senso di blocchi numerici ben strutturati con etichette brevi e concise, tal volta i dati da trattare sono stringhe multilinea o, peggio, sono dati numerici ma con romanzi al posto delle etichette (vezzo diffusissimo tra i miei colleghi burocrati) ... giusto per dare un esempio, un tipico caso :
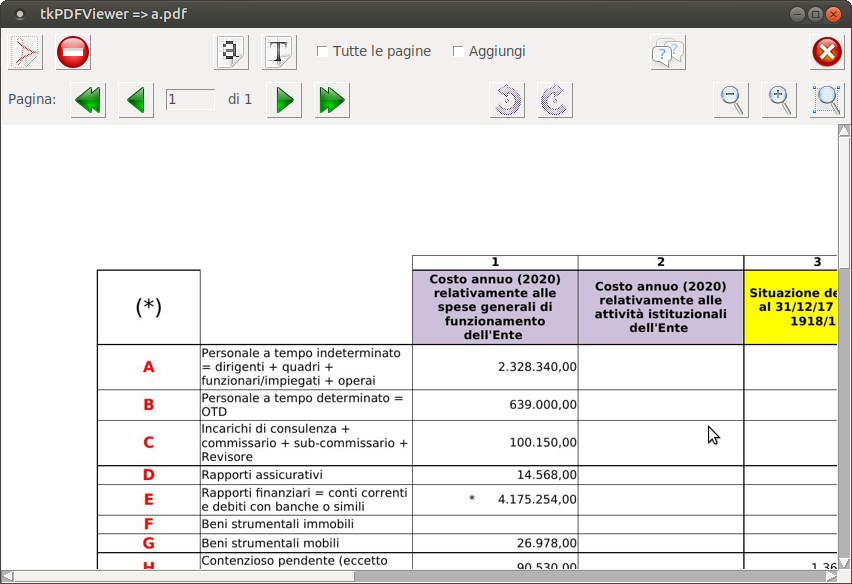
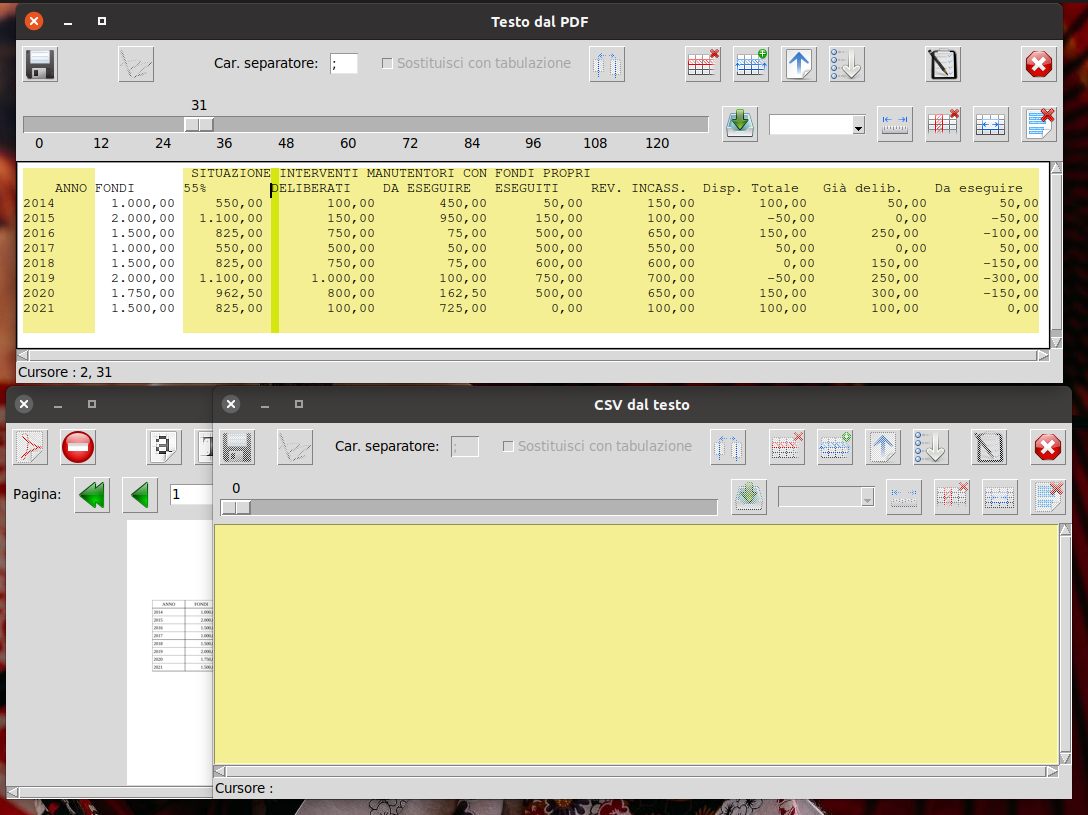
Si tratta di un PDF in formato A3 orizzontale con etichette orizzontali e verticali multi-riga e variamente giustificate ... il nostro
pdftotext (con lo OCR è intrattabile) è in grado di estrarre correttamente il testo, anche di tenere un incolonnamento
approssimativamente congruo ma per le righe ... beh, non sono proprio perfette!
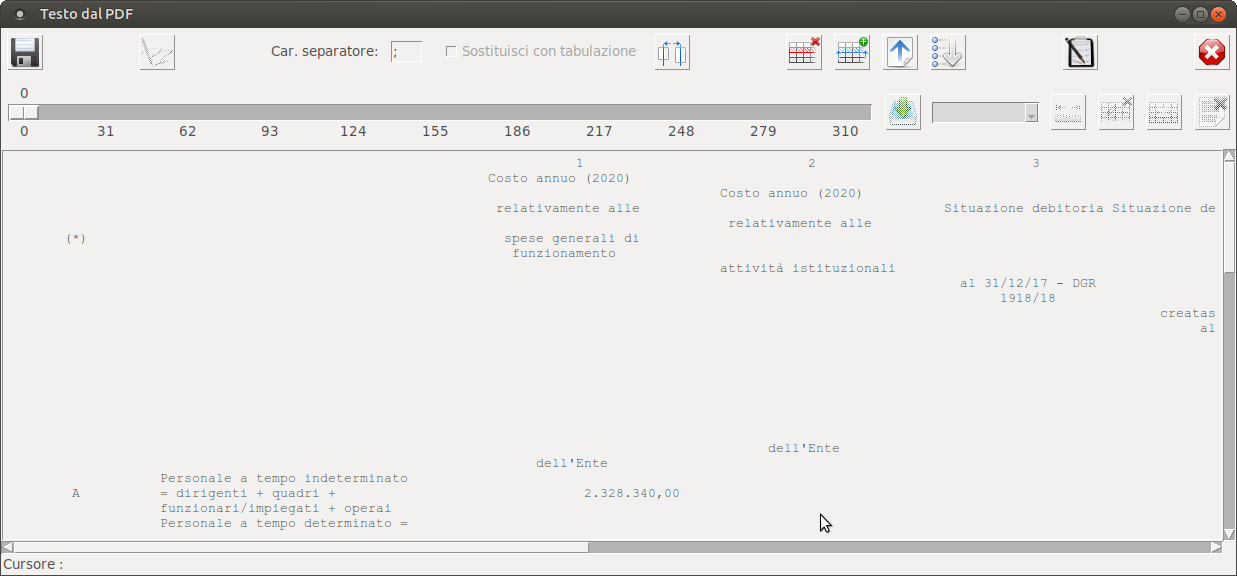
Un caso del genere comporta una certa attenzione in ciò che si fa, i posizionamenti di riga sono in genere attendibili ma non sempre i dati sono sulle stesse righe che contengono le etichette. Comunque, ci si trova in una condizione nella quale occorre indicare alla applicazione che alcune righe vanno considerate quale un unico elemento. Pur potendo effettuare tale operazione con la definizione delle colonne attivata (e senza le quali non avrebbe effetto), trovo che tale concomitanza confonde, principalmente trattando fogli dati piuttosto ampi.
La progressione migliore, una volta definito il testo da trattare è in primo luogo individuare le righe extra-dati da eliminarsi, selezionarle e cancellarle utilizzando il pulsante "
Cancella righe, quindi passare alla
Definizione delle unioni di righe
Effettuare una unione di righe, per l'utente, è una operazione piuttosto semplice, gli basterà selezionare le righe da unire presenti nel controllo di testo e premere il pulsante "
Unisci righe", prendiamo ad esempio l'immagine soprastante, per definire la seconda riga dati bisognerà cliccare sulla 2
a e, tenendo il pulsante premuto, trascinare la selezione sino alla 21
a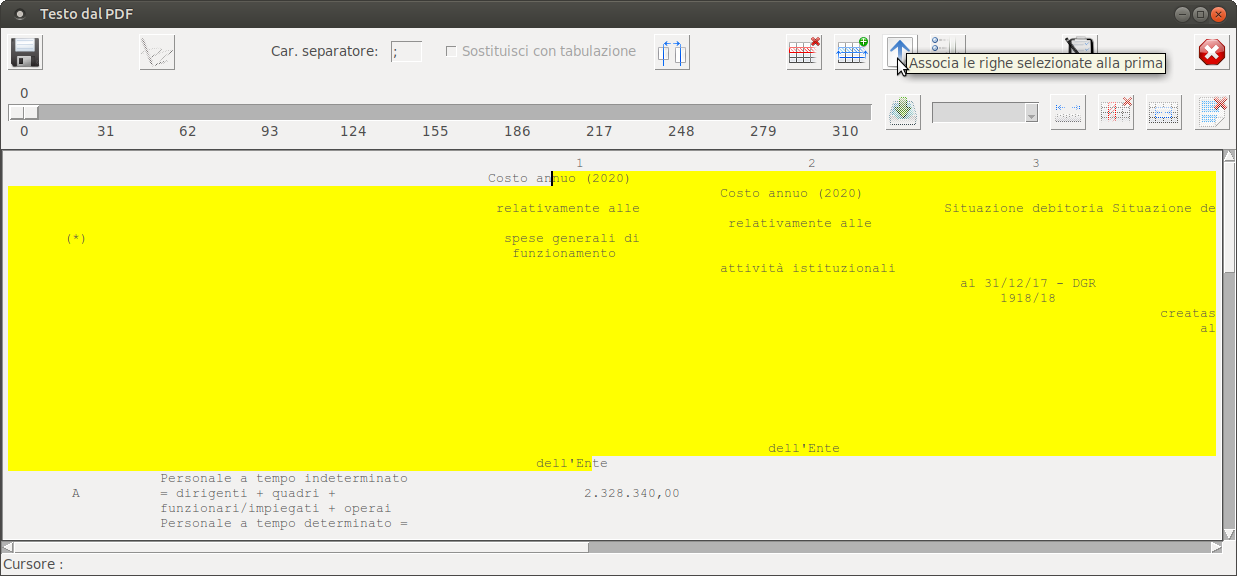
quindi premere il pulsante "
Unisci righe", ripetendo poi l'operazione per le altre righe interessate
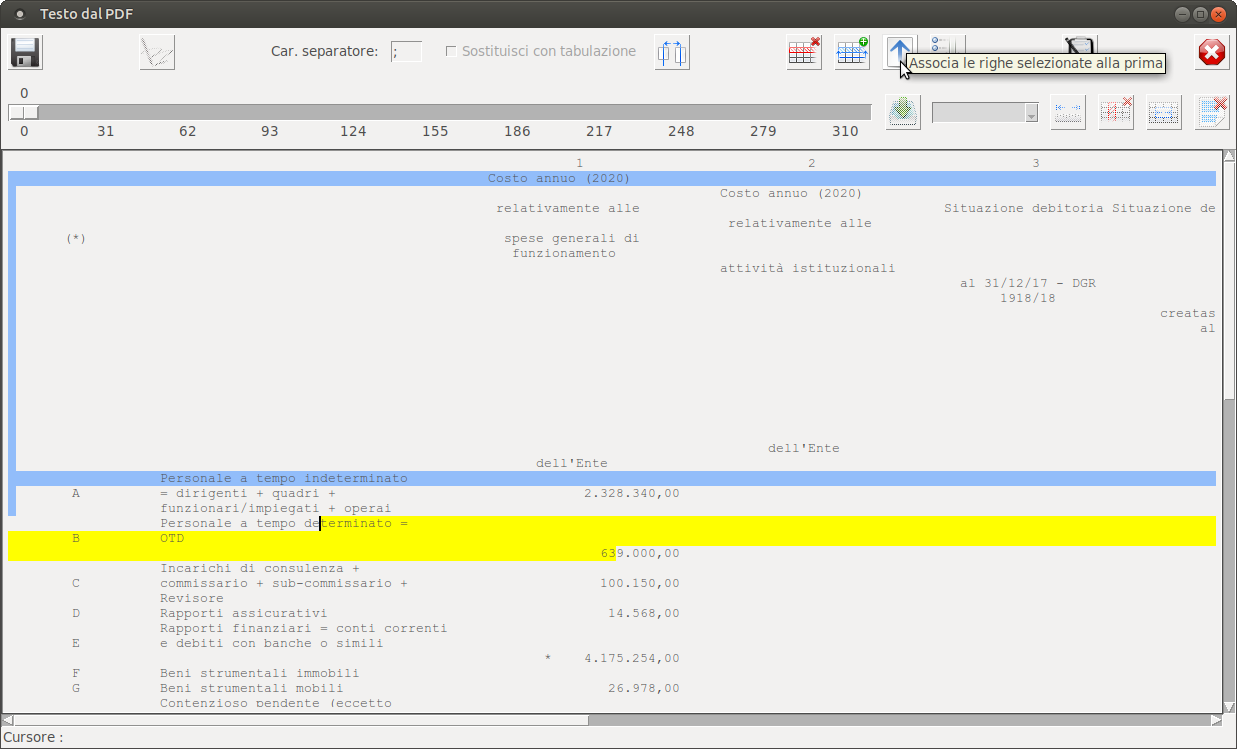
Le righe "unite" avranno l'intera prima riga e la prima colonna di tutte le altre righe interessate con un celestino quale colore di background, per facilitare all'utente la visualizzazione di quanto fatto.
Dal nostro punto di vista di programmatori, o aspiranti tali quale lo scrivente

, la pressione del pulsante "
Unisci righe" (
self.bt_merge nel codice) avvierà il callback "
_merge_rows(self)" che provvederà ad estrarre l'intervallo di righe selezionate in
self.pdf_text, se vi sono più righe selezionate controllerà che nessuna di esse ricada in un intervallo di unione già definito, se tutto è "in ordine" verrà formata una lista degli indici di riga delle righe comprese nella unione, detta lista verrà aggiunta alla variabile di istanza
self.merge_rows (anch'essa una lista) ed invocherà il metodo di classe
_repaint_row_columns() che, tra le altre cose, applicherà il tag "
r_merge" a tutti i caratteri della prima riga dell'unione ed al primo carattere delle altre.
Ovviamente, è prevedibile avvengano errori nella impostazione delle unioni di righe, in tal caso sarà sufficiente posizionare il cursore in una delle righe appartenenti all'unione errata e premere il pulsante "
Dividi righe" (
self.bt_nomerge nel codice) il cui callback (
_no_merge_rows(self)) provvederà ad identificare ed eliminare l'elemento interessato di
self.merge_rows ed invocare il ridisegno dell'area di testo.
i callbacksCODICE
def _merge_rows(self):
if self.pdf_text.tag_ranges(tk.SEL):
init_index = self.pdf_text.index(tk.SEL_FIRST)
end_index = self.pdf_text.index(tk.SEL_LAST)
else:
init_index = self.pdf_text.index(tk.INSERT)
end_index = init_index
first = int(init_index.split('.')[0])
last = int(end_index.split('.')[0])
if first == last: return
for r in range(first, last+1):
for mr in self.merge_rows:
if r in mr:
message = 'Riga %d già compresa in precedente accorpamento' % r
msg = mydialog.Message(self).show_warning(message,
title='Posizione incongrua')
mydialog.center_win(msg)
return
self.merge_rows.append([x for x in range(first, last+1)])
self._repaint_row_columns()
def _no_merge_rows(self):
curr_index = int(self.pdf_text.index(tk.INSERT).split('.')[0])
for i in range(len(self.merge_rows)):
if curr_index in self.merge_rows[i]:
del(self.merge_rows[i])
break
self._repaint_row_columns()
Come detto, sarebbe cosa buona e giusta eseguire separatamente le fasi di definizione delle unioni di righe e di definizione delle colonne, comunque sono processi logicamente "separati" che possono essere eseguiti contemporaneamente.
La definizione di unioni di righe, come già detto, non ha effetti se non vi è una contemporanea definizione di colonne, per contro una definizione di colonne può agire anche in assenza di definizione di unioni di righe : considererà le singole righe per definire una griglia di celle da elaborare per l'estrazione dati.
In assenza di unioni di righe l'elaborazione considererà il testo della singola riga compreso tra le ordinate di inizio e fine di una colonna, ripulito dei caratteri "spazio" a sinistra e destra, quale singolo dato.
In presenza di unioni di righe l'elaborazione considererà il testo delle singole righe facenti parte dell'unione e compreso tra le ordinate di inizio e fine di una colonna, ripulito dei caratteri "spazio" a sinistra e destra e sommato con inserzione di uno spazio intermedio, quale singolo dato.
Definizione delle colonne
Una cosa non ancora detta è che l'area di testo contenente i dati da impostare è configurata con un font a passo fisso ed ha inibito il ritorno a capo "automatico" (proprietà "
wrap='none allo instanziamento di
self.pdf_text), ciò per rendere il più lineare possibile il lavoro di un user ... e poi, lavoriamo sulle righe

Per altro, una volta avviata la modalità di impostazione per un CSV, viene immediatamente eseguita una valutazione delle righe di testo (ripetuta ad ogni eventuale ulteriore aggiunta di testo) che pareggerà la lunghezza di tutte le righe-dati alla dimensione maggiore, tale operazione viene effettuata con chiamate al metodo "
_def_max_len(self)" di
TextUtilityCODICE
def _def_max_len(self):
text = self.pdf_text.get('1.0', 'end-1c')
rows = text.split('\n')
maximo = 0
for r in rows:
if len(r) > maximo: maximo = len(r)
if maximo > self.maximo:
self.maximo = maximo
self.sc_columns.configure(from_=0, to=self.maximo,
tickinterval=self.maximo//10)
# ricodifica il testo aggiungendo spazi per raggiungere sempre il massimo
self.pdf_text.delete("1.0", "end-1c")
for r in rows:
r += ' ' * (self.maximo-len(r))
self.pdf_text.insert('end', r + '\n')
Gli accorgimenti sopra esposti hanno la ben precisa finalità di ottenere una dimensione di testo visivamente "regolare", ossia che tutti i caratteri di indice "x" delle varie righe di testo presenti abbiano le stesse ordinate visuali e che comunque
esistano su ogni riga caratteri in corrispondenza sino alla più alta "x" esistente ... cosa non garantita dalla estrazione di
pdftotext (provare per credere).
Quanto sopra è realizzato per far visualizzare all'user il
punto di inizio della definizione di una colonna, tale "punto di inizio" è costituito dalla colorazione verde-giallino di background per i caratteri con una determinata posizione "x" in tutte le righe, la colorazione è effettuata applicando il tag "
defcol" ai caratteri.
Riguardo alla definizione della "posizione x" da parte dell'utente sono state implementate due possibili modalità.
Una volta avviata la modalità di definizione delle colonne dati l'utente potrà cliccare, col tasto sinistro del mouse, nel punto voluto dell'area di testo
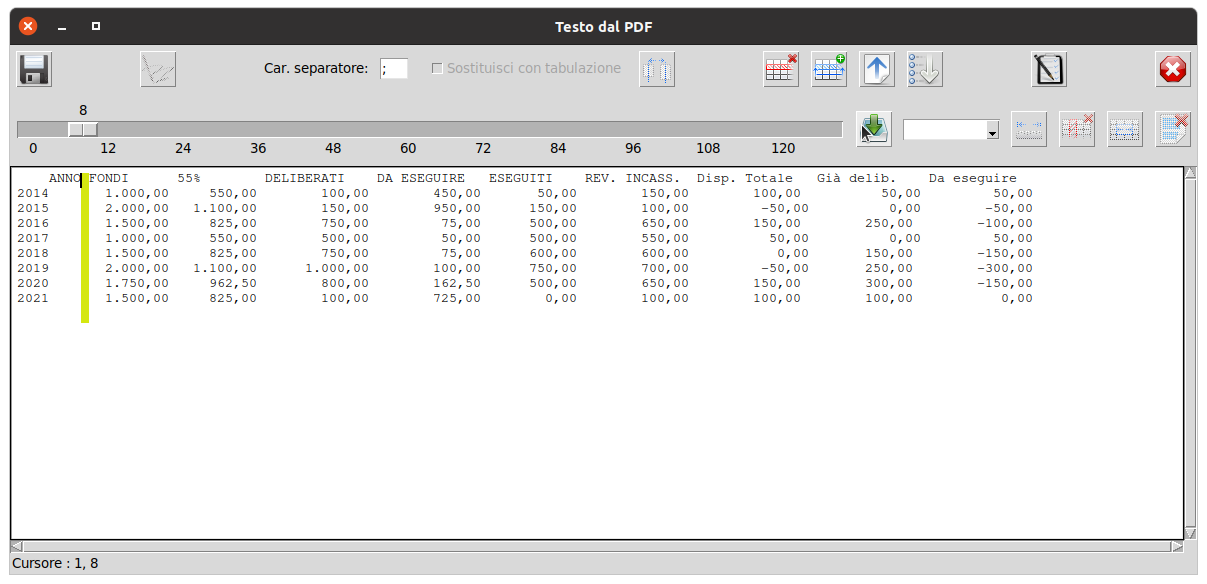
vedrà comparire la barra verde-giallo indicate il punto di inizio di una nuova colonna, si noti come in figura si estenda un paio di righe oltre il testo, basterà che prema il pulsante "
Inizio colonna" e su quella ordinata verrà impostato l'inizio di una nuova colonna dati.
Operativamente ho trovato tale metodo molto efficace e semplice, semplicità che, naturalmente, comporta un certo "lavoro" di implementazione, per ottenere tale "effetto" si è eseguito il binding per l'evento "
<button-1>" per
self.pdf_text collegandolo al callback "
_on_locate(self, evt)" il quale, verificato se è il giusto contesto, provoca il refresh del controllo, in maniera da avere la "giusta" posizione del cursore, e dopo una attesa di 10 millisecondi (per il refresh) invoca il metodo di classe "
_get_text_coords(self)" che provvede a leggere la posizione (riga/colonna, ovvero y/x) del cursore, che esporrà nella label in fondo alla finestra ("Cursore : 1, 8" in figura) ed imposterà l'ordinata quale valore di un controllo
tk.Scale (
self.sc_columns), è il binding di quest'ultimo,
_column_evidence(self, evt=None), in realtà, a "fare il lavoro" di colorazione, che è indipendente dal cursore, come potete vedere nella sottostante figura
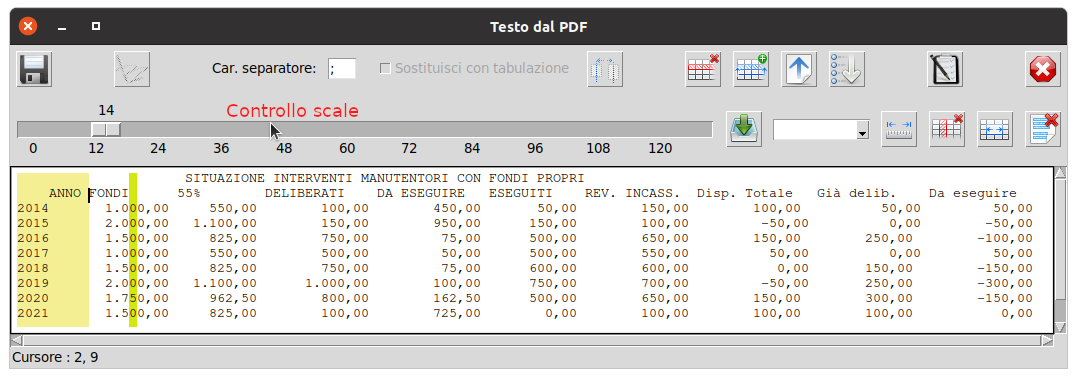
ed è il valore (
value) corrente nel controllo scale che sarà valutato nel callback del pulsante "
Inizio colonna" (ovvero di
self.bt_confcol nel codice) che provvederà a valutare la "liceità" della nuova posizione e, nel caso, ad aggiungere "il nuovo" a
self.columns, aggiornare il combo-box e la finestra in generale
CODICE
def _def_new_column(self):
pos = self.sc_columns.get()
if pos == 0 or pos == self.maximo:
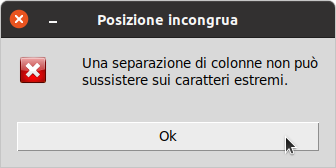
message = 'Una separazione di colonne non può\nsussistere sui caratteri estremi.'
msg = mydialog.Message(self).show_error(message,
title='Posizione incongrua')
mydialog.center_win(msg)
return
if self.columns:
for i in range(len(self.columns)):
if pos == self.columns[i][0] or pos == self.columns[i][1]:
message = "Una separazione di colonne non può\ngiacere all'inizio o alla fine di una colonna esistente"
msg = mydialog.Message(self).show_warning(message,
title='Posizione incongrua')
mydialog.center_win(msg)
return
if pos in range(self.columns[i][0]+2,self.columns[i][1]-1):
old1 = self.columns[:i]
old2 = self.columns[i+1:]
new = [(self.columns[i][0], pos-1, True), (pos, self.columns[i][1], True)]
self.columns = old1 + new + old2
break
else:
new = [(0, pos-1, True), (pos, self.maximo, True)]
self.columns = new
self._repaint_row_columns()
self._update_combo()
self._evaluate_context()
Si noti, nel codice sopra, che i singoli valori di
self.columns siano in realtà una tupla formata da due interi, costituenti la posizione di inizio e fine di una colonna, ed un valore booleano, inizialmente "Vero", che indica se la colonna è da valutarsi o meno nella elaborazione dei dati.
Una volta definita una colonna, sulla stessa potranno applicarsi un paio di proprietà, una di esse è la proprietà di essere "ignorata" nel corso della definizione dei dati CSV, la definiremo premendo il pulsante "
Ignora colonna" (
self.bt_ignorecol nel codice), la colonna verrà colorata di grigio applicando il rag "
not" ... e se abbiamo cliccato "a menga" lo ripremeremo (è uno switch), il callback (
_ignore_col(self)) si limita a ricreare la tupla utilizzando le stesse ordinate e la negazione del precedente stato del valore per "ignorata".
Analogamente, si comporta come uno switch il pulsante "
Attiva/Disattica conservazione spazi interni", ovvero
self.bt_spaces nel codice, il cui callback (
_switch_i_spaces(self)) provvederà ad aggiungere la colonna interessata nella lista
self.del_spaces, se non vi è contenuta, la eliminerà altrimenti, la colonna avrà applicato il tag "
no_space" ai caratteri della seconda riga, che apparirà con sfondo rossastro, nel caso sia attiva l'eliminazione degli spazi interni ... si tenga presente che, se presente, l'indice di una colonna verrà eliminato da self.del_spaces nell caso sulla stessa si traffichi con il pulsante "Ignora colonna".
Per altro, al fine di distinguerle, le varie colonne saranno alternativamente di colore bianco o giallo-verdino, per applicazioni ai caratteri in esse ricadenti dei tags "
even" ed "
odd".
Naturalmente si è previsto il caso di una impostazione errata di colonna, basterà posizionarsi sulla colonna "sbagliata" e premere il pulsante "
Rimuovi colonna", verrà eliminata e, se proprio avete combinato un pasticcio premete il pulsante "
Azzera impostazioni", saranno rimosse tutte le impostazioni di colonna e potrete ricominciare da capo.
Si rimanda al codice completo del modulo per approfondimenti sui callback non esposti. Forse, più interessante è la procedura
_elab_major richiamata da
_make_csv, callback di
self.bt_makecsv, quando
self.defcol è "Vero"
CODICE
def _elab_major(self):
if self.csv_win == None or not self.csv_win.winfo_exists():
return
sep = self.e_sep.get()
if len(sep) > 1: return
text_rows = self.pdf_text.get('1.0', tk.END).splitlines()
if not text_rows: return
index = 0
while index < len(text_rows):
# verifica se l'indice corrente ricade in una fusione di righe
merge_index = None
index += 1
cell_text = []
for i in range(len(self.merge_rows)):
if index in self.merge_rows[i]:
merge_index = i
break
if merge_index != None:
cell_x = self.merge_rows[merge_index]
index = self.merge_rows[merge_index][-1]
else:
cell_x = [index]
for y in range(len(self.columns)):
cell_text.append(self._get_cell_text(cell_x, y))
for item in cell_text:
if item == None:
cell_text.remove(item)
csv_text = sep.join(cell_text)
self.csv_win.add_text(csv_text)
def _get_cell_text(self, cell_x, y):
response = ''
for r in cell_x:
text = self.pdf_text.get(str(r)+'.0', str(r)+'.end')
if self.columns[y][2]:
text = text[self.columns[y][0]:self.columns[y][1]+1]
text = text.lstrip()
text = text.rstrip()
else:
return None
response += ' ' + text
response = response.lstrip()
response = response.rstrip()
if y in self.del_spaces:
response = response.replace(' ', '')
return response
In tale processo viene scandito il testo presente nell'area di testo da elaborare, in primo luogo, è definita una lista di indici
cell_x* di riga costituita dalla singola riga in esame se non presente in una fusione di riga, ovvero dagli elementi di
self.merge_rows che la comprendono (in tal caso la riga corrente è riposizionata all'indice più alto dell'elemento in self.merge_rows), viene, quindi, invocato il metodo
_get_cell_text(self, cell_x, y)* su ogni singolo elemento di self.columns definito.
* la scelta dei nomi x, y e cell_x è infelice e fuorviante dato che x tratta numeri di riga (quindi ascisse) ed y tratta numeri di colonna dei caratteri (quindi ordinate), in futuro vi sarà indicazione più congrua_get_cell_text estrarrà il testo compreso nei limiti di colonna (y[0] ed y[1]) di ogni riga memorizzata in cell_x e lo memorizzerà in una singola stringa che, ripulito degli spazi se la colonna è compresa in self.del_spaces, verrà restituito se la colonna non è da ignorare, in tal caso verrà restituito "
None".
Il valore restituito viene memorizzato nella lista
cell_text, scandite tutte le colonne verranno, quindi, eliminati i valori "None" e quindi costruita la limea dati CSV, unendo i vari elementi con il carattere separatore, che verrà inviata alla finestra per i dati CSV.
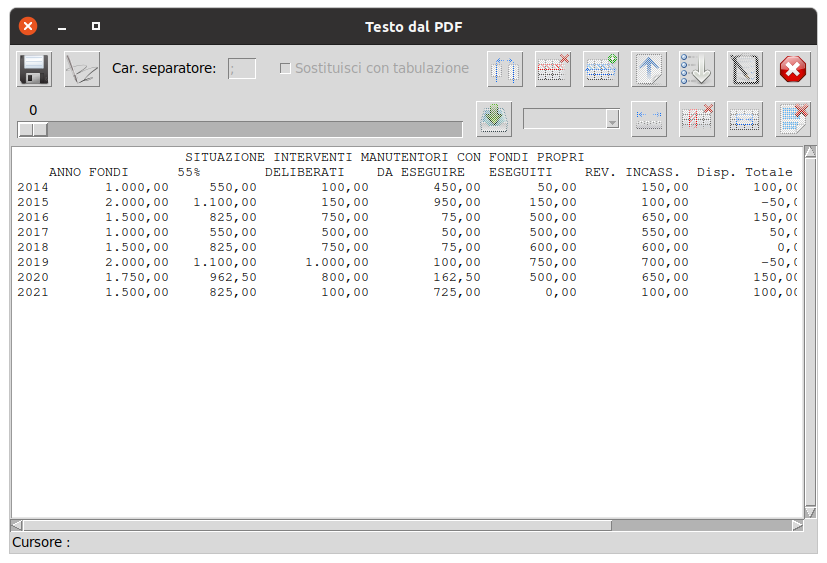
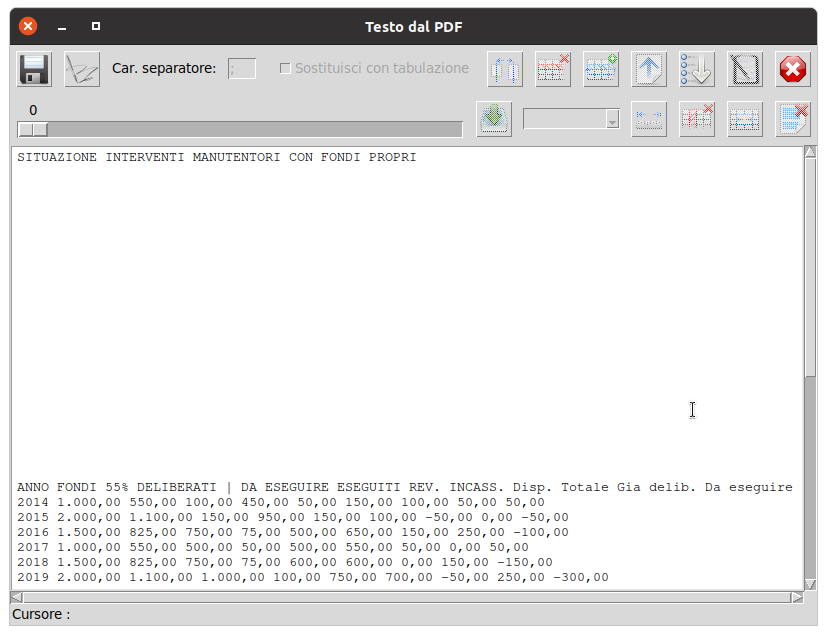
In pratica, supponendo di aver impostato in tal modo i dati da elaborare :
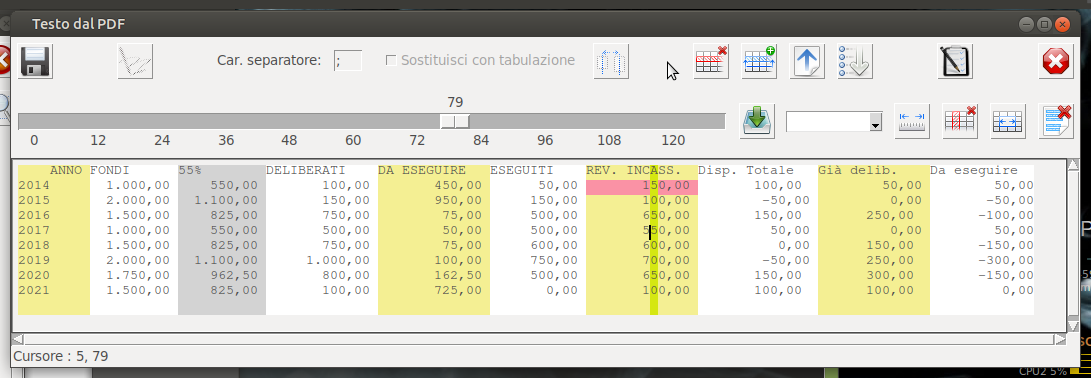
Otterremo i dati CSV sotto riportati
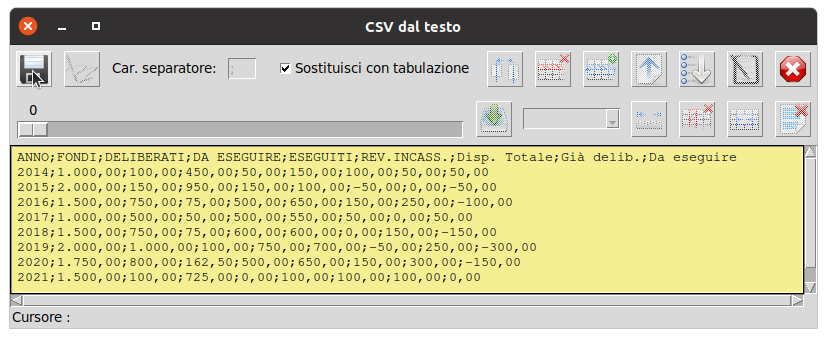
Non ci rimarrà altro che spuntare la casella
Sostituisci con tabulazione, nel caso volessimo un tab UTF-32 quale separatore, altrimenti sarà il carattere separatore di elaborazione, e preme il pulsante "
Salva" per ottenere il nostro file dati CSV.
Ora il codice completo di
textutility.py (626 righe)
CODICE
#-*- coding: utf-8 -*-
import tkinter as tk
from tkinter import ttk
import tkinter.filedialog as fdlg
from text_ico_and_tip import IcoDispencer
from my_tk_object import CreaToolTip as ctt
import mydialog
class TextUtility(tk.Toplevel):
colours = ['white', '#f4ef93', '#D5E711', 'lightgray', '#92BDFA', '#FA92A5']
def __init__(self, master, type='text'):
super().__init__(master)
self.master = master
self.type = type
self.state = 'no_work'
self.edit = False
self.defcol = False
self.maximo = 0
self.columns = []
self.merge_rows = []
self.del_spaces = []
self.csv_win = None
self._populate()
self._evaluate_context()
def _populate(self):
if self.type == 'text':
self.title('Testo dal PDF')
elif self.type == 'csv':
self.title('CSV dal testo')
else:
self.title('%s : Stato non definito' % self.type)
ids = IcoDispencer()
# toolbar
p_tools = tk.Frame(self)
p_tools.grid(row=0, column=0, sticky='ew')
self.ico_save = tk.PhotoImage(data=ids.getIco('salva'))
self.bt_save = tk.Button(p_tools, image=self.ico_save,
command=self._on_save)
bt_save_ttp = ctt(self.bt_save, ids.getDescr('salva'))
self.bt_save.grid(row=0, column=0, padx=5, pady=5)
self.ico_edit = tk.PhotoImage(data=ids.getIco('edit_csv'))
self.bt_edit = tk.Button(p_tools, image=self.ico_edit,
command=self._on_edit)
bt_edit_ttp = ctt(self.bt_edit, ids.getDescr('edit_csv'))
self.bt_edit.grid(row=0, column=2, padx=5, pady=5)
lbl = tk.Label(p_tools, text='Car. separatore:', anchor='w',
padx=5, pady=5)
lbl.grid(row=0, column=4)
self.e_sep = tk.Entry(p_tools, width=3)
self.e_sep.insert(tk.END, ';')
self.e_sep.grid(row=0, column=5, padx=5)
message = 'Carattere utilizzato come separatore dati (solo modalità testo)'
e_sep_ttp = ctt(self.e_sep, message)
self.chk_var = tk.BooleanVar()
self.chk_var.set(False)
self.chk_tab = tk.Checkbutton(p_tools, text='Sostituisci con tabulazione',
var= self.chk_var, padx=5, pady=5,
justify='left')
message = 'Sostituisce il carattere di separazione con la codifica di tabulazione (solo modalità CSV)'
chk_tab_ttp = ctt(self.chk_tab, message)
self.chk_tab.grid(row=0, column=6, padx=5, pady=5)
self.ico_defcol = tk.PhotoImage(data=ids.getIco('def_col'))
self.bt_defcol = tk.Button(p_tools, image=self.ico_defcol,
command=self._on_defcol)
bt_defcol_ttp = ctt(self.bt_defcol, ids.getDescr('def_col'))
self.bt_defcol.grid(row=0, column=7, padx=5, pady=5)
self.ico_delrows = tk.PhotoImage(data=ids.getIco('del_row'))
self.bt_delrows = tk.Button(p_tools, image=self.ico_delrows,
command=self._del_select_rows)
bt_delrows_ttp = ctt(self.bt_delrows, ids.getDescr('del_row'))
self.bt_delrows.grid(row=0, column=9, padx=5, pady=5)
self.ico_trafrows = tk.PhotoImage(data=ids.getIco('trasf_row'))
self.bt_trafrows = tk.Button(p_tools, image=self.ico_trafrows,
command=self._trasf_rows)
bt_trafrows_ttp = ctt(self.bt_trafrows, ids.getDescr('trasf_row'))
self.bt_trafrows.grid(row=0, column=10, padx=5, pady=5)
self.ico_merge = tk.PhotoImage(data=ids.getIco('merge_rows'))
self.bt_merge = tk.Button(p_tools, image=self.ico_merge,
command=self._merge_rows)
bt_merge_ttp = ctt(self.bt_merge, ids.getDescr('merge_rows'))
self.bt_merge.grid(row=0, column=11, padx=5, pady=5)
self.ico_nomerge = tk.PhotoImage(data=ids.getIco('no_row_merge'))
self.bt_nomerge = tk.Button(p_tools, image=self.ico_nomerge,
command=self._no_merge_rows)
bt_nomerge_ttp = ctt(self.bt_nomerge, ids.getDescr('no_row_merge'))
self.bt_nomerge.grid(row=0, column=12, padx=5, pady=5)
self.ico_makecsv = tk.PhotoImage(data=ids.getIco('make_csv'))
self.bt_makecsv = tk.Button(p_tools, image=self.ico_makecsv,
command=self._make_csv)
bt_makecsv_ttp = ctt(self.bt_makecsv, ids.getDescr('make_csv'))
self.bt_makecsv.grid(row=0, column=14, padx=5, pady=5)
self.ico_close = tk.PhotoImage(data=ids.getIco('close'))
self.bt_close = tk.Button(p_tools, image=self.ico_close,
command=self.destroy)
bt_close_ttp = ctt(self.bt_close, ids.getDescr('close'))
self.bt_close.grid(row=0, column=16, padx=5, pady=5)
p_tools.grid_columnconfigure(1, weight=1)
p_tools.grid_columnconfigure(3, weight=1)
p_tools.grid_columnconfigure(8, weight=1)
p_tools.grid_columnconfigure(13, weight=1)
p_tools.grid_columnconfigure(15, weight=1)
# gestione colonne
p_cols = tk.Frame(self)
p_cols.grid(row=1, column=0, sticky='ew')
self.sc_columns = tk.Scale(p_cols, from_=0, to=0, orient=tk.HORIZONTAL,
command=self._column_evidence)
message = 'imposta il punto iniziale per una nuova colonna'
sc_columns_ttp = ctt(self.sc_columns, message)
self.sc_columns.grid(row=0, column=0, padx=5, pady=5, sticky='ew')
self.ico_confcol = tk.PhotoImage(data=ids.getIco('conf_col'))
self.bt_confcol = tk.Button(p_cols, image=self.ico_confcol,
command=self._def_new_column)
bt_confcol_ttp = ctt(self.bt_confcol, ids.getDescr('conf_col'))
self.bt_confcol.grid(row=0, column=1, padx=5, pady=5)
self.cmb_col = ttk.Combobox(p_cols, values=[], width=10, state='readonly')
message = 'Elenco delle colonne dati definite (formato : num_inizio num_fine)'
cmb_col_tpp = ctt(self.cmb_col, message)
self.cmb_col.grid(row=0, column=2, padx=5, pady=5)
self.ico_spaces = tk.PhotoImage(data=ids.getIco('save_space'))
self.bt_spaces = tk.Button(p_cols, image=self.ico_spaces,
command=self._switch_i_spaces)
bt_spaces_ttp = ctt(self.bt_spaces, ids.getDescr('save_space'))
self.bt_spaces.grid(row=0, column=3, padx=5, pady=5)
self.ico_ignorecol = tk.PhotoImage(data=ids.getIco('ignore_col'))
self.bt_ignorecol = tk.Button(p_cols, image=self.ico_ignorecol,
command=self._ignore_col)
bt_ignorecol_ttp = ctt(self.bt_ignorecol, ids.getDescr('ignore_col'))
self.bt_ignorecol.grid(row=0, column=4, padx=5, pady=5)
self.ico_removecol = tk.PhotoImage(data=ids.getIco('remove_col'))
self.bt_removecol = tk.Button(p_cols, image=self.ico_removecol,
command=self._remove_column)
bt_removecol_ttp = ctt(self.bt_removecol, ids.getDescr('remove_col'))
self.bt_removecol.grid(row=0, column=5, padx=5, pady=5)
self.ico_nocols = tk.PhotoImage(data=ids.getIco('no_cols'))
self.bt_nocols = tk.Button(p_cols, image=self.ico_nocols,
command=self._restart_cols)
bt_nocols_ttp = ctt(self.bt_nocols, ids.getDescr('no_cols'))
self.bt_nocols.grid(row=0, column=6, padx=5, pady=5)
p_cols.grid_columnconfigure(0, weight=1)
p_text = tk.Frame(self)
p_text.grid(row=2, column=0, sticky='nsew')
self.pdf_text = tk.Text(p_text, font='courier 10',
selectbackground="yellow",
wrap='none', padx=5, pady=5)
self.pdf_text.tag_config('even', background=self.colours[0])
self.pdf_text.tag_config('odd', background=self.colours[1])
self.pdf_text.tag_config('r_merge', background=self.colours[4])
self.pdf_text.tag_config('not', background=self.colours[3])
self.pdf_text.tag_config('no_space', background=self.colours[5])
self.pdf_text.tag_config('defcol', background=self.colours[2])
self.pdf_text.tag_raise('sel')
if self.type == 'csv':
self.pdf_text.configure(bg='#f4ef93')
self.pdf_text.grid(row=0, column=0, sticky='nsew')
v_scr_1 = tk.Scrollbar(p_text, orient=tk.VERTICAL,
command=self.pdf_text.yview)
self.pdf_text.configure(yscrollcommand=v_scr_1.set)
v_scr_1.grid(row=0, column=1, sticky='ns')
h_scr_1 = tk.Scrollbar(p_text, orient=tk.HORIZONTAL,
command=self.pdf_text.xview)
self.pdf_text.configure(xscrollcommand=h_scr_1.set)
h_scr_1.grid(row=1, column=0, sticky='ew')
self.lbl_message = tk.Label(p_text, text='Cursore : ', justify='left')
self.lbl_message.grid(row=2, column=0, columnspan=2, sticky='w')
p_text.grid_columnconfigure(0, weight=1)
p_text.grid_rowconfigure(0, weight=1)
self.grid_columnconfigure(0, weight=1)
self.grid_rowconfigure(2, weight=1)
# bindings
self.pdf_text.bind('<Button-1>', self._on_locate)
# ***************************
# *** CALLBACK'S ***
# ***************************
def _on_save(self):
if self.type == 'csv':
self._write_csv()
else:
self._write_text()
self._evaluate_context()
def _on_edit(self):
if self.csv_win == None or not self.csv_win.winfo_exists():
self.csv_win = TextUtility(self, type='csv')
try:
self._verify_sep()
except ValueError as e:
message = 'Errore separatore : {0}'.format(e)
msg = mydialog.Message(self).show_warning(message,
title='Separatore incongruo')
mydialog.center_win(msg)
self.edit = True
self._def_max_len()
self._evaluate_context()
def _on_defcol(self):
self.defcol = True
self._evaluate_context()
def _on_locate(self, evt):
if self.type != 'text': return
if not self.defcol: return
self.pdf_text.update()
self.after(10, self._get_text_coords)
def _get_text_coords(self):
y, x = self.pdf_text.index(tk.INSERT).split('.')
msg = 'Cursore : ' + y + ', ' + x
self.lbl_message.configure(text=msg)
self.sc_columns.set(int(x))
def _del_select_rows(self):
rows = self._get_rows_intervall()
if not rows: return
rows.reverse()
for n in rows:
self.pdf_text.delete(str(n)+'.0', str(n)+'.end + 1 char')
def _trasf_rows(self):
rows = self._get_rows_intervall()
if not rows: return
for row in rows:
text = self.pdf_text.get(str(row )+ '.0', str(row) + '.end')
self.csv_win.add_text(text)
rows.reverse()
for n in rows:
self.pdf_text.delete(str(n)+'.0', str(n)+'.end + 1 char')
def _make_csv(self):
try:
self._verify_sep()
except ValueError as e:
message = 'Errore separatore : {0}'.format(e)
msg = mydialog.Message(self).show_error(message,
title='Separatore incongruo')
mydialog.center_win(msg)
return
sep = self.e_sep.get()
self.csv_win.set_separator(sep)
if not self.defcol:
self._elab_minor()
else:
self._elab_major()
def _column_evidence(self, evt=None):
self.pdf_text.tag_remove('defcol', '1.0', 'end')
last_row = int(self.pdf_text.index('end').split('.')[0])
pos = self.sc_columns.get()
for r in range(1, last_row+1):
self.pdf_text.tag_add('defcol', '%d.%d' % (r, pos),
'%d.%d' %(r, pos+1))
def _def_new_column(self):
pos = self.sc_columns.get()
if pos == 0 or pos == self.maximo:
message = 'Una separazione di colonne non può\nsussistere sui caratteri estremi.'
msg = mydialog.Message(self).show_error(message,
title='Posizione incongrua')
mydialog.center_win(msg)
return
if self.columns:
for i in range(len(self.columns)):
if pos == self.columns[i][0] or pos == self.columns[i][1]:
message = "Una separazione di colonne non può\ngiacere all'inizio o alla fine di una colonna esistente"
msg = mydialog.Message(self).show_warning(message,
title='Posizione incongrua')
mydialog.center_win(msg)
return
if pos in range(self.columns[i][0]+2,self.columns[i][1]-1):
old1 = self.columns[:i]
old2 = self.columns[i+1:]
new = [(self.columns[i][0], pos-1, True), (pos, self.columns[i][1], True)]
self.columns = old1 + new + old2
break
else:
new = [(0, pos-1, True), (pos, self.maximo, True)]
self.columns = new
self._repaint_row_columns()
self._update_combo()
self._evaluate_context()
def _switch_i_spaces(self):
if not self.columns: return
pos = self.sc_columns.get()
for i in range(len(self.columns)):
start = self.columns[i][0]
end = self.columns[i][1]
if pos in range(start, end+1):
if i in self.del_spaces:
self.del_spaces.remove(i)
elif self.columns[i][2]:
self.del_spaces.append(i)
break
self._repaint_row_columns()
def _ignore_col(self):
if not self.columns: return
pos = self.sc_columns.get()
for i in range(len(self.columns)):
start = self.columns[i][0]
end = self.columns[i][1]
if pos in range(start, end+1):
col = i
break
data = (self.columns[col][0], self.columns[col][1], not self.columns[col][2])
self.columns[col] = data
if col in self.del_spaces:
self.del_spaces.remove(col)
self._repaint_row_columns()
def _remove_column(self):
if not self.columns: return
pos = self.sc_columns.get()
for i in range(len(self.columns)):
start = self.columns[i][0]
end = self.columns[i][1]
if pos in range(start, end+1):
col = i
break
if col == 0: return
data = (self.columns[col-1][0], self.columns[col][1], True)
self.columns[col-1] = data
del(self.columns[col])
for c in self.del_spaces:
if c >= col: self.del_spaces.remove(c)
self._repaint_row_columns()
def _restart_cols(self):
self.columns = []
self.del_spaces = []
self._repaint_row_columns()
def _merge_rows(self):
if self.pdf_text.tag_ranges(tk.SEL):
init_index = self.pdf_text.index(tk.SEL_FIRST)
end_index = self.pdf_text.index(tk.SEL_LAST)
else:
init_index = self.pdf_text.index(tk.INSERT)
end_index = init_index
first = int(init_index.split('.')[0])
last = int(end_index.split('.')[0])
if first == last: return
for r in range(first, last+1):
for mr in self.merge_rows:
if r in mr:
message = 'Riga %d già compresa in precedente accorpamento' % r
msg = mydialog.Message(self).show_warning(message,
title='Posizione incongrua')
mydialog.center_win(msg)
return
self.merge_rows.append([x for x in range(first, last+1)])
self._repaint_row_columns()
def _no_merge_rows(self):
curr_index = int(self.pdf_text.index(tk.INSERT).split('.')[0])
for i in range(len(self.merge_rows)):
if curr_index in self.merge_rows[i]:
del(self.merge_rows[i])
break
self._repaint_row_columns()
# ***************************
# *** METODI DELLA CLASSE ***
# ***************************
def set_text(self, text):
'''Imposta il testo nell'area di visualizzazione cancellando il precedente.
e tutte le impostazioni effettuate'''
self.edit = False
self.defcol = False
self.maximo = 0
self.columns = []
self.merge_rows = []
self.del_spaces = []
if self.csv_win and self.csv_win.winfo_exists():
self.csv_win.close()
self.pdf_text.delete("1.0", "end-1c")
data = text.split('\n')
for row in data:
self.pdf_text.insert('end', row +'\n')
self._evaluate_context()
def add_text(self, text):
'''Aggiunge del testo nell'area di visualizzazione.'''
data = text.split('\n')
for row in data:
self.pdf_text.insert('end', row +'\n')
if self.edit: self._def_max_len()
self._evaluate_context()
def _def_max_len(self):
text = self.pdf_text.get('1.0', 'end-1c')
rows = text.split('\n')
maximo = 0
for r in rows:
if len(r) > maximo: maximo = len(r)
if maximo > self.maximo:
self.maximo = maximo
self.sc_columns.configure(from_=0, to=self.maximo,
tickinterval=self.maximo//10)
# ricodifica il testo aggiungendo spazi per raggiungere sempre il massimo
self.pdf_text.delete("1.0", "end-1c")
for r in rows:
r += ' ' * (self.maximo-len(r))
self.pdf_text.insert('end', r + '\n')
def _verify_sep(self):
text = self.pdf_text.get("1.0", "end-1c")
sep = self.e_sep.get()
if len(sep) > 1: raise ValueError('Carattere separatore composto da più caratteri')
if not sep: raise ValueError('Carattere separatore nullo')
if sep in text: raise ValueError('Carattere separatore contenuto nel testo')
def _evaluate_context(self):
self.bt_save.configure(state='disabled')
self.bt_edit.configure(state='disabled')
self.e_sep.configure(state='disabled')
self.chk_tab.configure(state='disabled')
self.bt_defcol.configure(state='disabled')
self.bt_merge.configure(state='disabled')
self.bt_spaces.configure(state='disabled')
self.bt_delrows.configure(state='disabled')
self.bt_trafrows.configure(state='disabled')
self.bt_makecsv.configure(state='disabled')
self.sc_columns.configure(state='disabled')
self.bt_confcol.configure(state='disabled')
self.cmb_col.configure(state='disabled')
self.bt_ignorecol.configure(state='disabled')
self.bt_removecol.configure(state='disabled')
self.bt_nocols.configure(state='disabled')
self.update()
if len(self.pdf_text.get('1.0', 'end-1c')) == 0:
self.state = 'no_work'
else:
self.bt_save.configure(state='normal')
self.state = 'work'
if self.state == 'no_work':
return
if self.state == 'work' and self.type == 'text':
if self.edit:
self.e_sep.configure(state='normal')
self.bt_delrows.configure(state='normal')
self.bt_trafrows.configure(state='normal')
self.bt_merge.configure(state='normal')
self.bt_makecsv.configure(state='normal')
self.bt_close.configure(state='normal')
if self.defcol:
self.sc_columns.configure(state='normal')
self.bt_confcol.configure(state='normal')
self.cmb_col.configure(state='normal')
if len(self.cmb_col['values']) > 0:
self.bt_spaces.configure(state='normal')
self.bt_ignorecol.configure(state='normal')
self.bt_removecol.configure(state='normal')
self.bt_nocols.configure(state='normal')
else:
self.bt_defcol.configure(state='normal')
else:
self.bt_edit.configure(state='normal')
elif self.type == 'csv' and self.state == 'work':
self.bt_save.configure(state='normal')
self.chk_tab.configure(state='normal')
def _get_rows_intervall(self):
if self.pdf_text.tag_ranges(tk.SEL):
init_index = self.pdf_text.index(tk.SEL_FIRST)
end_index = self.pdf_text.index(tk.SEL_LAST)
else:
init_index = self.pdf_text.index(tk.INSERT)
end_index = init_index
first = int(init_index.split('.')[0])
last = int(end_index.split('.')[0])
return [x for x in range(first, last+1)]
def _repaint_row_columns(self):
self.pdf_text.tag_remove('even', '1.0', 'end')
self.pdf_text.tag_remove('odd', '1.0', 'end')
self.pdf_text.tag_remove('r_merge', '1.0', 'end')
self.pdf_text.tag_remove('not', '1.0', 'end')
self.pdf_text.tag_remove('no_space', '1.0', 'end')
self.pdf_text.tag_remove('defcol', '1.0', 'end')
last_row = int(self.pdf_text.index('end').split('.')[0])
for i in range(len(self.columns)):
start = self.columns[i][0]
end = self.columns[i][1] + 1
for r in range(1, last_row+1):
if self.columns[i][2]:
if i % 2:
self.pdf_text.tag_add('even', '%d.%d' % (r, start), '%d.%d' %(r, end))
else:
self.pdf_text.tag_add('odd', '%d.%d' % (r, start), '%d.%d' %(r, end))
else:
self.pdf_text.tag_add('not', '%d.%d' % (r, start), '%d.%d' %(r, end))
for c in self.del_spaces:
start = self.columns[c][0]
end = self.columns[c][1] + 1
self.pdf_text.tag_add('no_space', '%d.%d' % (2, start), '%d.%d' %(2, end))
for coll in self.merge_rows:
self.pdf_text.tag_add('r_merge', '%d.0' % coll[0], '%d.end' % coll[0])
for i in range(1, len(coll)):
r = coll[i]
self.pdf_text.tag_add('r_merge', '%d.0' % r, '%d.1' % r)
def _update_combo(self):
self.cmb_col.delete(0, tk.END)
col_list = []
for c in self.columns:
item = str(c[0]) + ' ' + str(c[1])
col_list.append(item)
self.cmb_col['values'] = col_list
def _elab_minor(self):
if self.csv_win == None or not self.csv_win.winfo_exists():
return
rows = self._get_rows_intervall()
if not rows: return
sep = self.e_sep.get()
if len(sep) > 1: return
if not sep: return
for n in rows:
text = self.pdf_text.get(str(n)+'.0', str(n)+'.end')
words = text.split()
text = sep.join(words)
self.csv_win.add_text(text)
rows.reverse()
for n in rows:
self.pdf_text.delete(str(n)+'.0', str(n)+'.end + 1 char')
def _elab_major(self):
if self.csv_win == None or not self.csv_win.winfo_exists():
return
sep = self.e_sep.get()
if len(sep) > 1: return
text_rows = self.pdf_text.get('1.0', tk.END).splitlines()
if not text_rows: return
index = 0
while index < len(text_rows):
# verifica se l'indice corrente ricade in una fusione di righe
merge_index = None
index += 1
cell_text = []
for i in range(len(self.merge_rows)):
if index in self.merge_rows[i]:
merge_index = i
break
if merge_index != None:
cell_x = self.merge_rows[merge_index]
index = self.merge_rows[merge_index][-1]
else:
cell_x = [index]
for y in range(len(self.columns)):
cell_text.append(self._get_cell_text(cell_x, y))
for item in cell_text:
if item == None:
cell_text.remove(item)
csv_text = sep.join(cell_text)
self.csv_win.add_text(csv_text)
def _get_cell_text(self, cell_x, y):
response = ''
for r in cell_x:
text = self.pdf_text.get(str(r)+'.0', str(r)+'.end')
if self.columns[y][2]:
text = text[self.columns[y][0]:self.columns[y][1]+1]
text = text.lstrip()
text = text.rstrip()
else:
return None
response += ' ' + text
response = response.lstrip()
response = response.rstrip()
if y in self.del_spaces:
response = response.replace(' ', '')
return response
def set_separator(self, sep):
old_state = self.e_sep['state']
self.e_sep.configure(state='normal')
self.e_sep.delete(0, tk.END)
self.e_sep.insert(0, sep)
self.e_sep.configure(state=old_state)
def _write_text(self):
f_types = [('file testo', '*.txt')]
f_name = fdlg.asksaveasfilename(parent=self,
title='Registrazione testo',
confirmoverwrite=False,
filetypes=f_types)
if not f_name: return
text = self.pdf_text.get('1.0', 'end-1c')
try:
with open(f_name, 'w') as f:
f.write(text)
except OSError:
message = 'Errore scrittura file'
msg = mydialog.Message(self).show_warning(message,
title='Salvataggio fallito')
mydialog.center_win(msg)
def _write_csv(self):
f_types = [('Comma separed values', '*.csv')]
f_name = fdlg.asksaveasfilename(parent=self,
title='Creazione CSV',
confirmoverwrite=False,
filetypes=f_types)
if not f_name: return
text = self.pdf_text.get('1.0', 'end-1c')
if self.chk_var.get():
sep = self.e_sep.get()
text = text.replace(sep, '\U00000009')
try:
with open(f_name, 'w') as f:
f.write(text)
except OSError:
message = 'Errore scrittura file'
msg = mydialog.Message(self).show_warning(message,
title='Salvataggio fallito')
mydialog.center_win(msg)
def close(self):
self.destroy()
La parte tkinter finisce qui ... ora provo a vedere cosa mi riesce di fare con le wxPython! ... sarà in prossimo post
Ciao
Edited by nuzzopippo - 9/7/2021, 12:30